
 开发者工具
开发者工具

 运营增长
运营增长

 数据洞察
数据洞察
 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








个推技术学院:日志传输带宽优化方法之Flume Avro实践
- 系统架构
 发表于2020年4月17日
发表于2020年4月17日

引言:
如何在有限的资源下解决性能瓶颈问题是运维永恒的痛点。这期文章,Mr.Tech邀请了在性能优化方面有着丰富经验的个推高级运维工程师白子画,为大家分享宽带优化之Flume Avro在个推的实践。在异地日志数据互传的场景下,我们从传输数据着手,借助Avro的特性使数据压缩率达80%以上,解决了个推在实际生产过程中遇到的带宽不够用的问题。本文我们将向大家介绍Flume Avro在数据传输过程中所承担的不同角色,以及如何保证数据的完整性和传输的高效性,并分享在实际业务中取得的优化效果。
1 背景
个推作为专业的数据智能服务商,已经成功服务了数十万APP,每日的消息下发量达百亿级别,由此产生了海量日志数据。为了应对业务上的各种需求,我们需要采集并集中化日志进行计算,为此个推选用了高可用的、高可靠的、分布式的Flume系统以对海量日志进行采集、聚合和传输。此外,个推也不断对Flume进行迭代升级,以实现自己对日志的特定需求。
原有的异地机房日志汇聚方式,整个流程相对来说比较简单,A机房业务产生的日志通过多种方式写入该机房Kafka集群,然后B机房的Flume通过网络专线实时消费A机房Kafka的日志数据后写入本机房的Kafka集群,所有机房的数据就是通过相同方式在B机房Kakfa集群中集中化管理。如图一所示:
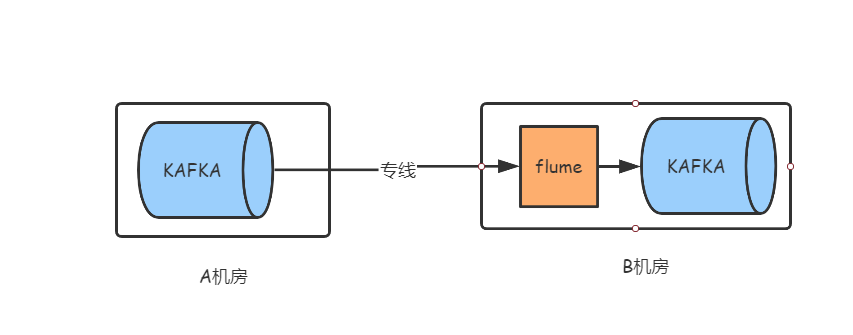
图一:原有异地日志传输模式
但是随着业务量的不断增加,日志数据在逐渐增多的过程中对带宽要求变高,带宽的瓶颈问题日益凸显。按照1G的专线带宽成本2~3w/月来计算,一个异地机房一年仅专线带宽扩容成本就高达30w以上。对此,如何找到一种成本更加低廉且符合当前业务预期的传输方案呢?Avro有可快速压缩的二进制数据形式,并能有效节约数据存储空间和网络传输带宽,从而成为优选方案。
2 优化思路
2.1 Avro简介
Avro是一个数据序列化系统。它是Hadoop的一个子项目,也是Apache的一个独立的项目,其主要特点如下:
- 丰富的数据结构;
- 可压缩、快速的二进制数据类型;
- 可持久化存储的文件类型;
- 远程过程调用(RPC);
- 提供的机制使动态语言可以方便地处理数据。
具体可参考官方网站: http://avro.apache.org/
2.2 Flume Avro方案
Flume的RPC Source是Avro Source,它被设计为高扩展的RPC服务端,能从其他Flume Agent 的Avro Sink或者Flume SDK客户端,接收数据到Flume Agent中,具体流程如图二所示:
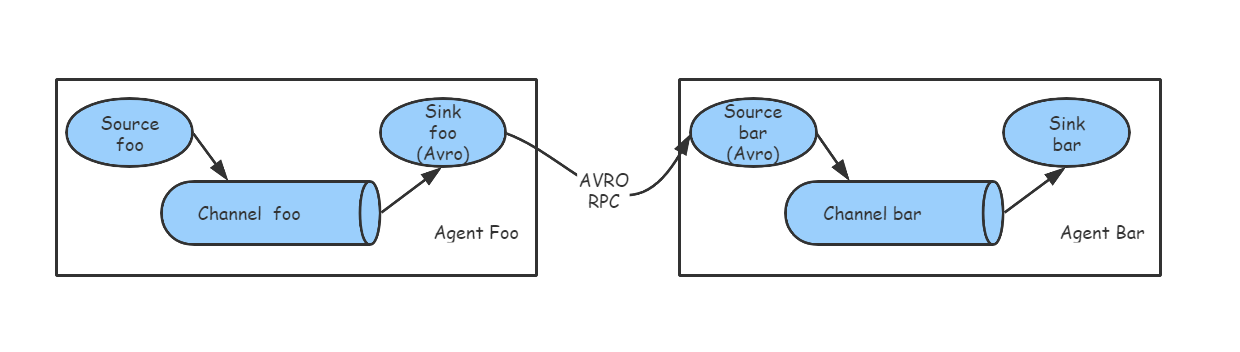
图二: Avro Source流程
针对该模式,我们的日志传输方案计划变更为A机房部署Avro Sink用以消费该机房Kafka集群的日志数据,压缩后发送到B机房的Avro Source,然后解压写入B机房的Kafka集群,具体的传输模式如图三所示:
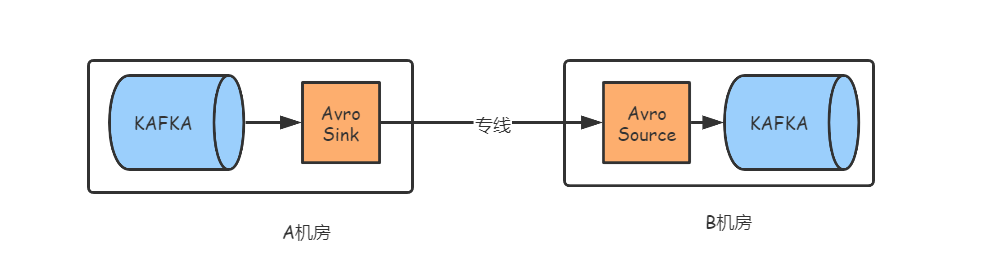
图三:Flume Avro传输模式
2.3 可能存在的问题
我们预估可能存在的问题主要有以下三点:
- 当专线故障的时候,数据是否能保证完整性;
- 该模式下CPU和内存等硬件的消耗评估;
- 传输性能问题。
3 验证情况
针对以上的几个问题,我们做了几项对比实验。
环境准备情况说明:
- 两台服务器168.10.81和192.168.10.82,以及每台服务器上对应一个Kakfa集群,模拟A机房和B机房;
- 两个Kafka集群中对应topicA(源端)和topicB(目标端)。在topicA中写入合计大小11G的日志数据用来模拟原始端日志数据。
- 168.10.82上部署一个Flume,模拟原有传输方式。
- 168.10.81服务器部署Avro Sink,192.168.10.82部署Avro Source,模拟Flume Avro传输模式。
3.1 原有Flume模式验证(非Avro)
- 监控Kafka消费情况:

- 81流量统计:

- 82流量统计:
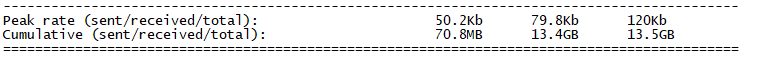
消费全部消息耗时:20min
消费总日志条数统计:129,748,260
总流量:13.5G
3.2 Avro模式验证
- 配置说明:
Avro Sink配置:
|
#kafkasink 是kafkatokafka的sinks的名字,可配多个,空格分开 kafkatokafka.sources.kafka_dmc_bullet.type = org.apache.flume.source.kafka.KafkaSource #source kafkasink_dmc_bullet的配置,可配置多个sink提高压缩传输效率 kafkatokafka.sinks.kafkasink_dmc_bullet.channel = channel_dmc_bullet #source kafkasink_dmc_bullet配的channel,只配一个
|
Avro Source配置:
|
#kafkasink 是kafkatokafka的sinks的名字,可配多个,空格分开 kafkatokafka.sources.kafka_dmc_bullet.type = avro #source kafkasink_dmc_bullet的配置 kafkatokafka.channels.channel_dmc_bullet.type = memory
|
- 监控Kafka消费情况

- 81流量统计:

- 82流量统计:

消费全部消息耗时:26min
消费总日志条数统计:129,748,260
总流量:1.55G
3.3 故障模拟
- 模拟专线故障,在A、B两机房不通的情况下,Avro Sink报错如下:
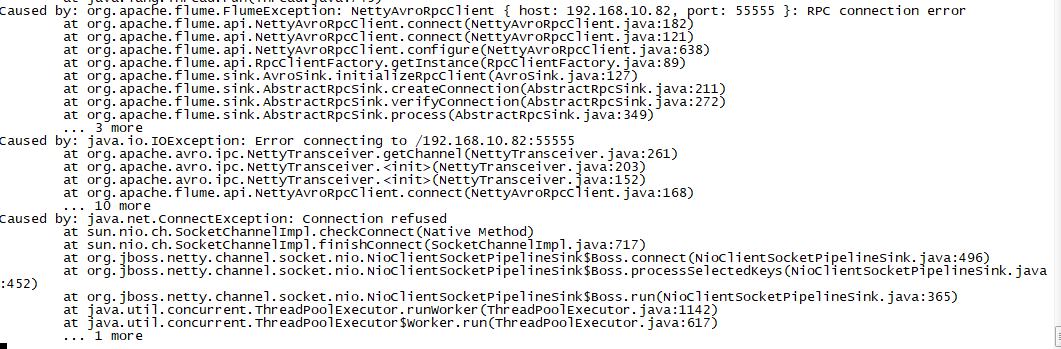
2.监控Kafka消费情况,发现消费者已停止消费:

3.故障处理恢复后继续消费剩余日志,经统计,总日志条数为:129,747,255。
3.4 结论
- 当专线发生故障时,正在网络传输中的通道外数据可能会有少部分丢失,其丢失原因为网络原因,与Avro模式无关;故障后停止消费的数据不会有任何的丢失问题,由于网络原因丢失的数据需要评估其重要性以及是否需要补传。
- 流量压缩率达80%以上,同时我们也测试了等级为1~9的压缩率,6跟9非常接近,CPU和内存的使用率与原有传输模式相差不大,带宽的优化效果比较明显。
- 传输性能由于压缩的原因适当变弱,单Sink由原先20分钟延长至26分钟,可适当增加Sink的个数来提高传输速率。
4 生产环境实施结果
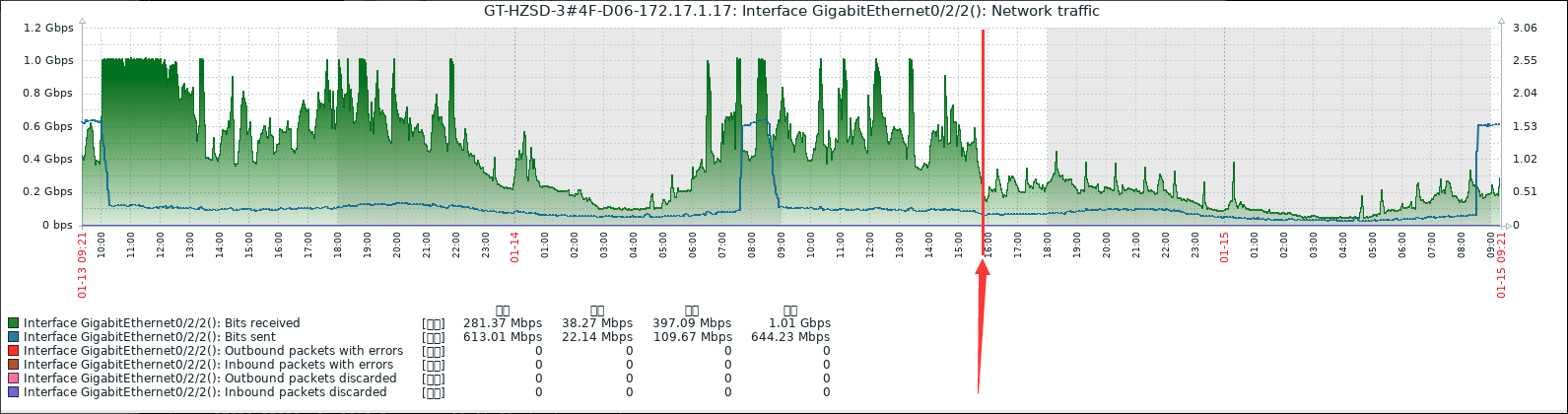
实施结果如下:
- 由于还有其它业务的带宽占用,总带宽使用率节省了50%以上,现阶段高峰期带宽速率不超过400Mbps;
- 每个Sink传输速率的极限大概是3000条每秒,压缩传输速率问题通过增加Sink的方式解决,但会适当增加CPU和内存的损耗。
5 全文总结
Flume作为个推日志传输的主要工具之一,Source的类型选择尤为重要(如avro、thrif、exec、kafka和spooling directory等等)。无论选择哪种Source,都是为了实现日志数据的高效传输。本文通过Avro的方式,解决了带宽资源瓶颈的问题。未来,让我们每一位开发者一起探索如何用更多的技术手段来节约控制成本,而不是单纯通过扩容硬件和网络来满足业务场景需求。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技









