
 开发者工具
开发者工具

 运营增长
运营增长

 数据洞察
数据洞察
 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








个推技术学院:后浪-移动互联网时代的数据中心设计
- 系统架构
 发表于2020年8月11日
发表于2020年8月11日

作者| 个推高级运维工程师 山川
前言
随着移动互联网的蓬勃发展,今天的数据中心和10年前的数据中心大为不同,无论从IDC的机器规模,还是流量模型都发生了很大变化。《前浪:传统数据中心的网络模型》已经为大家介绍了数据中心网络建设的基本要求、传统web时代的网络架构;本文将从以下几方面对移动互联网时代的数据中心进行一下介绍。
移动互联网时代的数据中心网络设计的目标是什么?
移动互联网时代数据中心的架构是怎样的?
Clos架构为何选择BGP作为路由协议?
数据中心中服务器双归路接入是怎样的?
01 互联网时代数据中心的设计目标
现代数据中心的演进都是由大型互联网公司的需求驱动的,数据中心的核心需求主要包括三个维度:
(1)端到端(server to server)的通信量
单体应用到微服务化的转变,导致南北向流量减少,东西向流量增加。
(2)规模
现代数据中心一个机房可能就有数万台服务器。
(3)弹性
传统数据中心的设计都是假设网络是可靠的,而现代数据中心应用都是假设网络是不可靠的,总会因为各种原因导致网络或机器故障。弹性就是要保证发生故障时,受影响的范围可控,故障后果可控。
现代数据中心网络必须满足以上三方面基本需求。
注:多租户网络需要额外考虑支持虚拟网络的快速部署和拆除。
02 现代数据中心网络架构
目前,大型互联网公司采用一种称为 Clos 的架构。Clos 架构最初是贝尔实验室的 Charles Clos 在 1950s 为电话交换网设计的。Clos设计可以实现无阻塞架构(non-blocking architecture),保障上下行带宽都充分利用。
(1)Clos架构由来
传统三层网络架构采用的“南北流量模型”,不适用于移动互联网环境。2008年,一篇题为《A scalable, commodity data center network architecture》的文章,首先提出将Clos架构应用在网络架构中。2014年,在Juniper的白皮书中,也提到了Clos架构。这一次,Clos架构应用到了数据中心网络架构中来。这是Clos架构的第三次应用。由于这种网络架构来源于交换机内部的Switch Fabric,因此这种网络架构也被称为Fabric网络架构。现在流行的Clos网络架构是一个二层的spine/leaf架构, spine交换机和leaf交换机之间是以full-mesh方式连接。
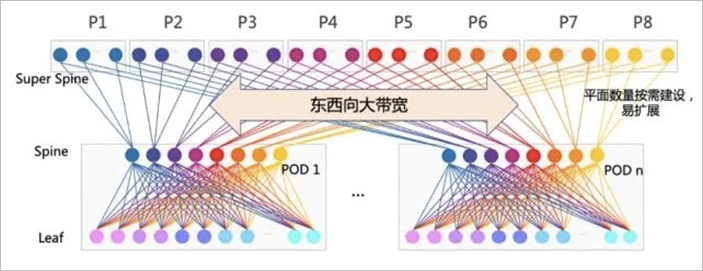
(2)Clos架构中交换机的角色
Clos架构中交换机有两种角色:leaf switch 和 spine switch。
leaf switch:相当于传统三层架构中的接入交换机,作为TOR(Top Of Rack)直接连接物理服务器。与接入交换机的区别在于,L2/L3网络的分界点现在是在leaf交换机上,leaf交换机之上则是三层网络。
spine switch:相当于核心交换机。spine和leaf交换机之间通过ECMP(Equal Cost Multi Path)动态选择多条路径。区别在于,spine交换机现在只是为leaf交换机提供一个弹性的L3路由网络,数据中心的南北流量可以选择从spine交换机发出,也可以与leaf交换机并行的交换机(edge switch)先连接,再从WAN/Core router中出去。
(3)Clos网络架构的特点:
a.连接的一致性(uniformity of connectivity):任意两个服务器之间都是 3 跳
b.节点都是同构的(homogeneous):服务器都是对等的,交换机/路由器也是
c.全连接(full-mesh):故障时影响面小(gracefully with failures);总带宽高 ,而且方便扩展,总带宽只受限于 Spine 的接口数量
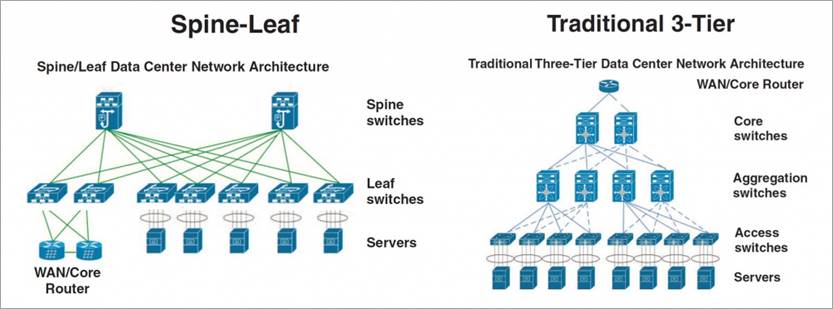
(4)Clos架构和传统三层网络对比
对比spine/leaf网络架构和传统三层网络架构,可以看出传统的三层网络架构是垂直的结构,而spine/leaf网络架构是扁平的结构。从结构看,spine/leaf架构更易于水平扩展。
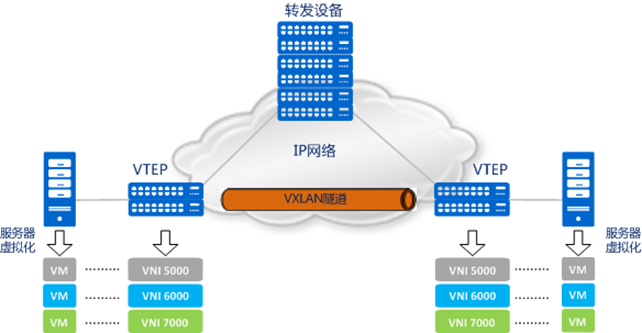
(5)移动互联时代二层技术Vxlan
Vxlan(虚拟扩展局域网),是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求。
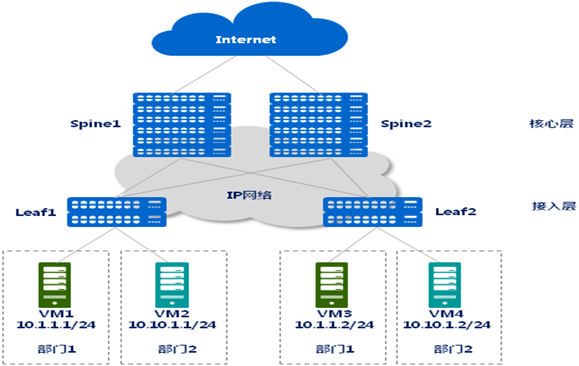
(6)Clos和Vxlan结合的逻辑二层网络模型
路由转发层面采用Clos组网模式,二层的虚拟机漂移用Vxlan技术隔离二层的广播域,兼具三层组网的灵活性,同时又避免了二层的环路和广播风暴问题。
03 Clos架构中为何选择BGP作为路由协议?
一、运营商和数据中心场景对比
在 BGP 应用于数据中心之前,它主要服务于提供商网络。这导致的一个问题就是,数据中心不能运行 BGP,否则会和底层供应商的网络相冲突。网络管理和运维人员,应重点关注这一点。
运营商和数据中心网络场景对比
数据中心:高密度连接
服务提供商:主要是区域间网络互联,相对低密度连接
服务提供商的网络首先需考虑可靠性,其次才是(路由等)变化的快速通知。因此,BGP 发送通知的实时性较弱。而在数据中心中,路由需要快速收敛。
另外,由于 BGP 自身的设计、行为,以及它作为路径矢量协议的特性,单个链路挂掉会导致节点之间发送大量 BGP 消息。BGP 从多个 ASN 收到一条 prefix(路由网段前缀)之后,最终只会生成一条最优路径。而在数据中心中,我们希望生成多条路径。为适配数据中心而对 BGP 进行的改造,大家可以自行查阅FRC 7938文档。
二、BGP从运营商环境适配到数据中心的改动
数据中心的改动以及需要考虑的因素主要涉及到以下几个方面:
各种路由协议
传统 BGP 从 OSPF、IS-IS、EIGRP等内部路由协议(internal routing protocols)接收路由通告,用于控制企业内的路由。因此不少人误以为要在数据中心中落地 BGP,还需要另一个协议。但实际上,在数据中心中 BGP 就是(特定的)内部路由协议,不需要再运行另一个协议了。
iBGP和eBGP
不少人在数据中心协议选择中存在一个误区,即认为在数据中心内部,就应该选择内部网关协议(iBGP)。实际上,在数据中心中, eBPG 的使用最为广泛,其主要原因是 eBGP 比 iBGP 更易理解和部署。iBGP 的最优路径选择算法很复杂,而且存在一些限制,其使用、配置、管理相对比较复杂,而eBGP 的实现比 iBGP 简单的多,可供我们选择的路径也比较多。
默认定时器导致的慢收敛
简而言之,BGP 中的几个定时器控制 peer 之间通信的速度。对于 BGP,这些参数的默认值都是针对服务提供商环境进行优化的,其中稳定性的优先级高于快速收敛。而数据中心则相反,快速收敛的优先级更高。
当一个节点挂掉,或挂掉之后恢复时,有四个定时器影响 BGP 的收敛速度。我们对这些参数进行调优,可以使BGP 达到内部路由协议(例如 OSFP)的性能,推荐配置如下:
Advertisement Interval
Keepalive and Hold Timers
Connect Timer
Advertisement Interval
Advertisement Interval
在发布路由通告的间隔内所产生的事件会被缓存,等时间到了一起发送。
默认:eBGP 是 30s,iBGP 是 0s。
对于密集连接型的数据中心来说,30s 显然太长了,0s 比较合适。这会使得eBGP 的收敛速度达到 OSFP 这种 IGP 的水平。
Keepalive and Hold Timers
每个节点会向它的 peer 发送心跳消息。如果一段时间内(称为 hold time)网络设备没收到 peer 的心跳,就会清除所有从这个 peer 收到的消息。
默认:
Keepalive: 60s
Hold timer: 180s
这表示每分钟发一个心跳,如果三分钟之内一个心跳都没收到,就认为 peer 挂了。数据中心中的三分钟太长了,足以让人“过完一生”。
典型配置
Keepalive: 3s
Hold timer: 9s
Connect Timer:节点和 peer 建立连接失败后,再次尝试建立连接之前需要等待的时长。
默认:60s。
数据中心默认 BGP 配置
很多 BGP 实现的默认配置都是针对服务提供商网络调优的,而不是针对数据中心。
建议:显示配置用到的参数(即使某些配置和默认值相同),这样配置一目了然,运维和排障都比较方便。
以下是 FRRouting BGP 的默认配置,我们认为是数据中心 BGP 的最优实践,供大家参考。
Multipath enabled for eBGP and iBGP
Advertisement interval: 0s
Keepalive and Hold Timers: 3s and 9s
Logging adjacency changes enabled
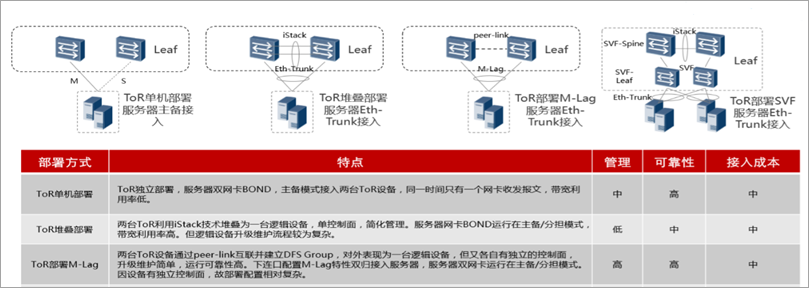
04 数据中心服务器接入技术概述
数据中心服务器接入主要采用以下三种模式:
(1)主备双上联模式 服务器网卡bond模式配置mode 0 ,链路双上联主备模式,Tor层面采用两台独立的交换机。
(2)链路捆绑双上联 服务器网卡bond模式配置mode 4 ,动态lacp协商,TOR交换机采用两台逻辑虚拟化部署,从设备和链路层逻辑上都呈现为传统二层模式,是当前用的较多的接入技术方案。
(3)M-lag 技术 服务器网卡bond模式配置mode 4 ,动态lacp协商,TOR交换机采用两台独立部署,中间加心跳线,运行M-lag协议。这个是国内设备厂家支持的通用技术。
IDC网络是上层应用的基础,稳定的网络建设才能为上层应用提供强大的支撑和保障。本文对IDC网络从PC时代到移动互联网时代的演进过程进行了总结,希望能给大家的网络建设提供一定的思路。个推也将持续关注网络发展趋势,不断探索多种应用场景,与开发者一起分享最新实践。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技









