开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








如何使Codis存储成本降低90%?个推:去吧,Pika!
- 大数据
- 系统架构
 发表于2022年3月18日
发表于2022年3月18日
作为一家数据智能公司,个推不仅拥有海量的关系型数据,也积累了丰富的key-value等非关系型数据资源。个推采用Codis保存大规模的key-value数据,随着公司kv类型数据的不断增加,使用原生的Codis搭建的集群所花费的成本越来越高。
在一些对性能响应要求不高的场景中,个推计划采用新的存储和管理方案以有效兼顾成本与性能。经过选型,个推引入了360开源的存储系统Pika作为Codis的底层存储,以替换成本较高的codis-server,管理分布式kv数据集群。
将Pika接入到Codis的过程并非一帆风顺,为了更好地满足业务场景需求,个推进行了系列设计和改造工作。本文是“大数据降本提效”专题的第四篇,为大家分享个推如何完美结合Pika和Codis,最终节省90%大数据存储成本的实战经验。

Codis的四大组件
在了解具体的迁移实战之前,需要先初步认识下Codis的基本架构。Codis 是一个分布式 Redis解决方案,由codis-fe、codis-dashboard、codis-proxy、codis-server等四个组件构成。
-
其中,codis-server是Codis中最核心和基础的组件。基于Redis 3版本,codis-server进行了功能扩展,但其本质上还是依赖于高性能的Redis提供服务。codis-server扩展了基于slot的key存储功能(为了实现slot这个功能,codis-server会额外占用超出存储数据所需的内存),并能够在Codis集群的不同Group之间进行slot数据热迁移。
-
codis-fe则提供对运维比较友好的管理界面,方便统一管理多套的codis-dashboard。
-
codis-dashboard负责管理slot、codis-proxy和ZooKeeper(或者etcd)等组件的数据一致性,整个集群的运维状态,数据的扩容缩容和组件的高可用,类似于k8s的api-server功能。
-
codis-proxy主要提供给业务层面使用的访问代理,负责解析请求路由并将key的路由信息路由到对应的后端group上面。此外,codis-proxy还有一个很重要的功能,即在通过codis-fe进行集群的扩缩容时,codis-proxy会根据group对应的slot的迁移状态触发key迁移的流程,能够实现在不中断业务服务的情况下热迁移数据,以确保业务的可用性。
Pika接入Codis的挑战
我们引入Pika主要是用来替换codis-server。作为360开源的类Redis存储系统,Pika底层选用RocksDB,它完全兼容Redis协议,并且主流版本提供Codis的接入能力。但在引入Pika以及将数据迁移到Codis的过程中,我们发现Pika和Codis的结合并非想象中完美。
问题一:语法不统一
在接入之前,我们深入查阅并对比了Pika和Codis源码,发现Pika实现的命令相对较少,将Pika接入到Codis之后有些功能还能否正常使用有待观察。
此外,codis-server和Pika支持的语法也有所不同。例如,如果要查看某一节点上slot 1的详细信息,Codis与Pika执行的命令分别如下:

也就是说,我们必须在codis-fe层命令调度与管理功能方面加上对Pika语法格式的支持。
针对此问题,我们在codis-dashboard层中,通过修改部分源码逻辑,实现了对Pika主从同步、主从提升等相关命令的支持,从而完成了在codis-fe层面的操作。
问题二:未成功完成数据迁移
完成了以上操作之后,我们便开始将kv数据迁移到Pika。然后,问题来了,我们发现虽然codis-fe界面上显示数据均已迁移完成,但实际上要迁移的数据并未被迁移到对应的集群。在codis-fe界面上,我们也未查看到明显的报错信息。
到底为何出现此问题呢?
我们继续查看了Pika有关slot的源码:
void
SlotsMgrtSlotAsyncCmd::Do(std::shared_ptr<Partition>
partition) { int64_t moved =
0;
int64_t remained =
0;
res_.AppendArrayLen(2);
res_.AppendInteger(moved);
res_.AppendInteger(remained);
}
我们发现,在日常的运行情况下,通过codis-dashboard发送给Pika的指令就是成功返回,这样codis-dashboard在迁移时立马就收到了成功的信号,然后就直接将迁移状态修改为成功,而其实此时数据迁移并没有被真的执行。
针对这种情况,我们查阅了有关Pika的官方文档 Pika配合Codis扩容案例。
从官方的文档来看,这种迁移方案是一种可能会丢数据的有损方案,我们需要根据自身情况来重新设计和调整迁移方案。
1.设计开发Pika迁移工具
首先,根据Codis的数据扩缩容原理,我们参考codis-proxy的架构设计,使用Go语言自行设计并开发了一套Pika数据迁移工具,目的是实现以下功能需求:
-
将Pika迁移工具伪装成一个Pika实例接入Codis并提供服务。
-
把Pika迁移工具作为一个流量转发工具,类似于codis-proxy,能够将对应slot的请求转发到指定的Pika实例上面,从而保证迁移过程中的业务可用性。
-
使Pika迁移工具能够感知到迁移过程中的主从同步情况,在主从完成的情况下可自动从节点断开,并将新增数据写入新集群,从而在流量分发过程中全力保证数据一致性。
2. 使用Pika迁移工具进行数据的热迁移
根据如上需求完成Pika迁移工具的设计开发后,我们就可以使用该工具对数据进行热迁移。迁移过程如下:
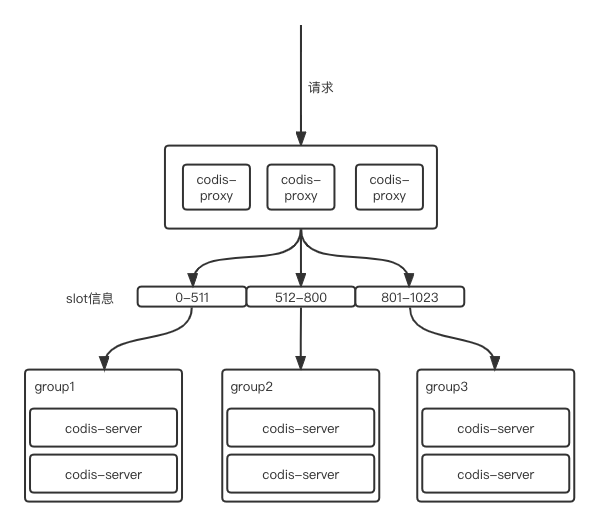
Step1: 集群原始状态
通过下图,可以看到,我们需要将801-1023中901-1023区间的slot信息迁移到新组件即Group4上,作为新实例提供服务。
Step2: 将Pika迁移工具接入Codis提供服务
在Pika迁移工具接入Codis之前,我们需将Group3中待迁移的901-1023作为Group4的主节点,并进行主从数据同步。此时Group3的901-1023作为主,Group4的901-1023作为从。在完成该步骤之后就可将Pika迁移工具接入Codis。
-
首先将801-1023的slot信息迁移到Pika迁移工具。
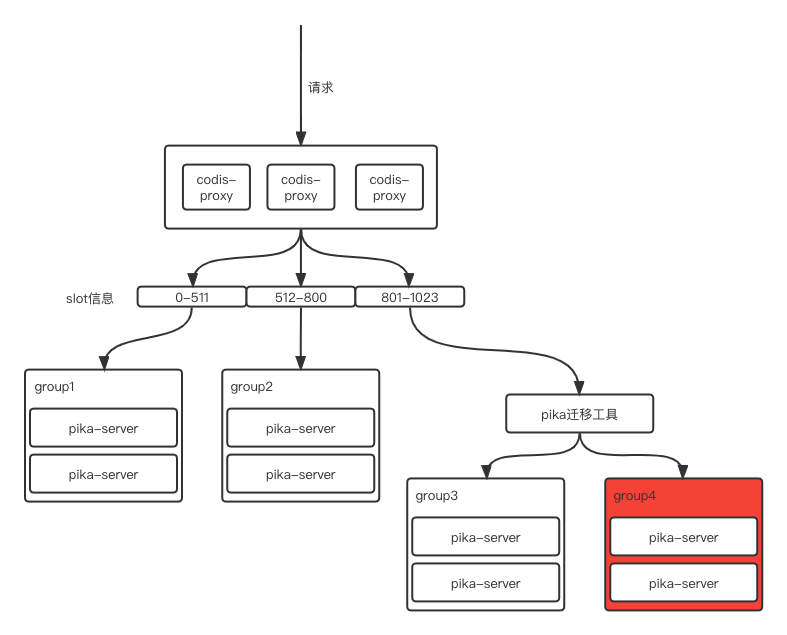
- 此时Pika迁移工具将801-900的读写信息写入Group3。
-
在Pika迁移工具中,将901-1023的读写信息同时指向Group4和Group3。然后进入下一步。
Step3: 主从同步数据并动态切换主从
此时Pika迁移工具已经完成接入,它将转发801-1023的slot请求到后端。
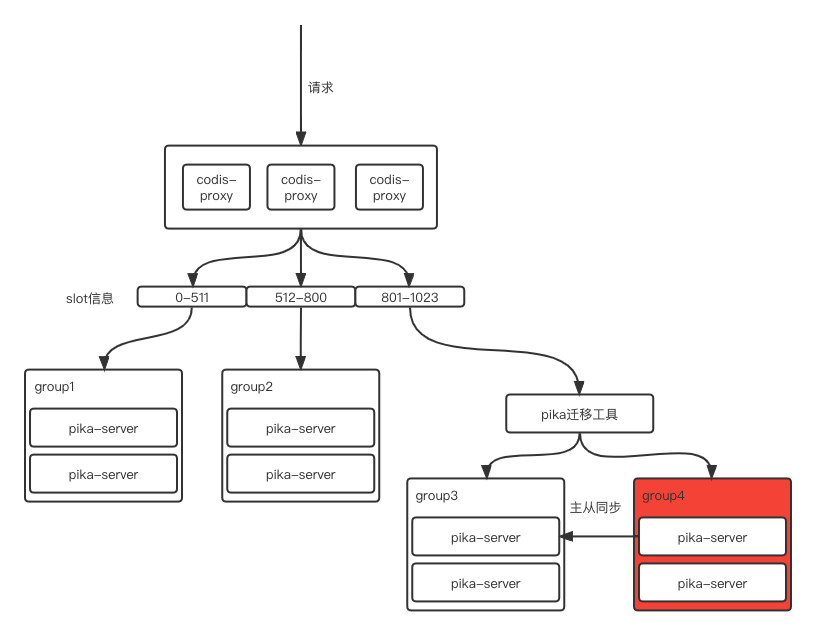
这里需要注意,Pika迁移工具在处理写流量时,会检查主从同步是否完成。
-
如果主从同步完成,Pika迁移工具会直接将Group4中Pika实例的从断掉,并将新数据写入到Group4中,否则就继续将写入的数据路由到Group3。
-
如果是读流量,Pika迁移工具会先尝试获取Group4的数据,如果获取到则返回,否则就去Group3获取数据。
-
如果901-1023的slot中没有写流量,则无法判断该slot主从同步是否完成以及是否要断开主从,那么我们可以向Pika迁移工具发送针对该slot的命令来执行该操作。
-
直到Group4中所有slot的主从同步完成且主从断开,方进行下一步。
下图比较形象地展示了Pika迁移工具的作业逻辑:
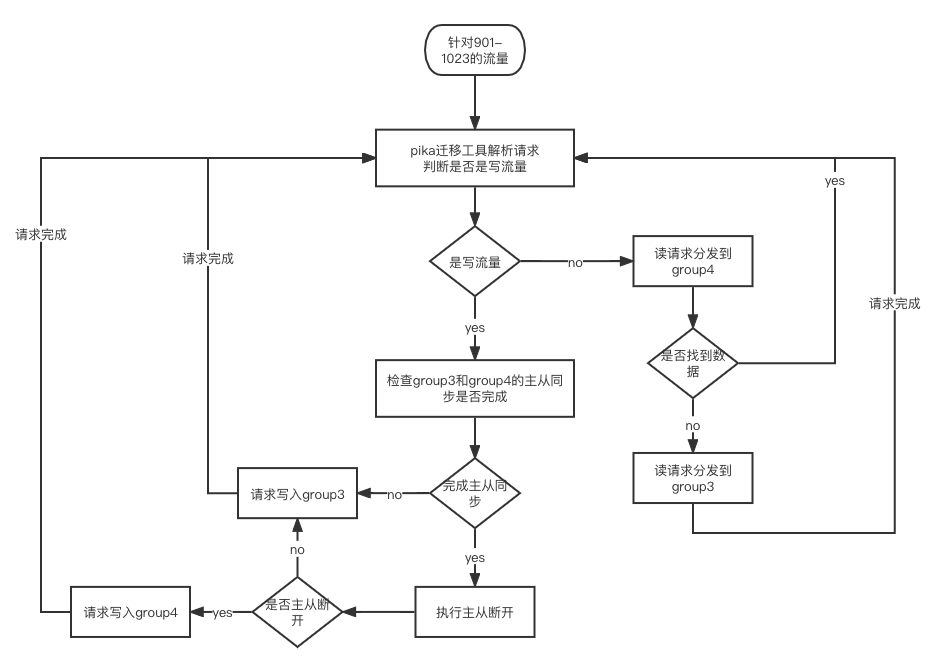
Step4: 将待迁移的slot迁入新的Group
在完成步骤3之后,再将Pika迁移工具的slot信息,即801-900,迁移回Group3,将901-1023迁移到Group4。
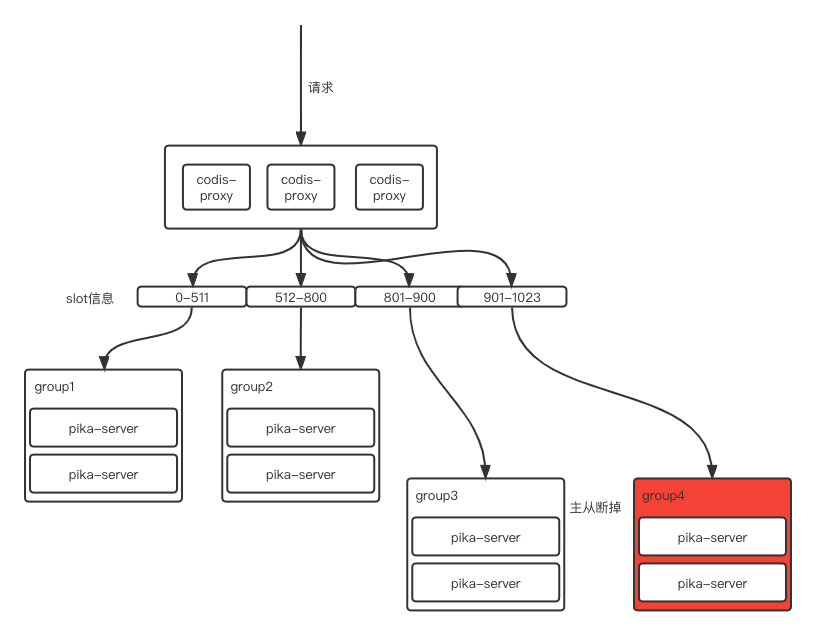
将901-1023完全迁移到Group4之后,就可将原来Group3中冗余的旧数据删除。至此,我们通过Pika迁移工具完成了对kv集群的扩容。
这里需要说明的是,Pika迁移工具的大部分功能和codis-proxy相似,只不过需要将对应的路由规则进行转换,并添加上支持Pika的语法指令。之所以能够如此设计实现,是因为在codis-proxy的迁移过程中产生的都是原子性命令的操作,从而能够在Pika迁移工具这一层拦截目标端的数据,并动态地将数据写入到对应的集群中。
方案效果实测
经过以上一系列的操作之后,我们成功使用Pika替换了原有的codis-server。那么我们预先的兼顾成本与性能的目标是否有达成呢?
首先,在性能方面,根据线上业务方的使用反馈,当前总体的业务服务p99值为250毫秒(包括对Codis和Pika的多次操作),能够满足当前现网对性能的需求。
再看成本方面,由于存储的key的数据结构类似,占用的实际物理空间基本相同。通过将Pika的数据转换成codis-server的存储量,内存使用大概为24/4*82 = 480G的内存空间。
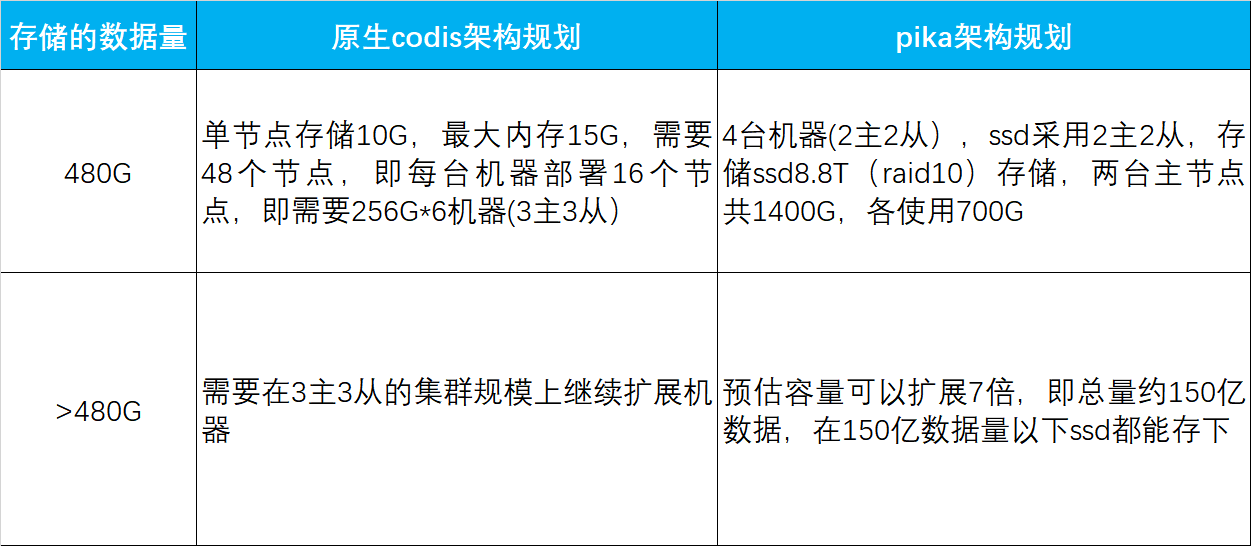
根据当前的运维经验,如果实际存储480G的数据,按照每个节点存储10G数据,单节点最大15G,需要48个节点,即需要256G*6台机器(3主3从)提供服务。
这样我们就可以得出结论:存储同等容量的数据,使用Pika的花费成本仅为Codis的5~10%!
真诚的选型建议
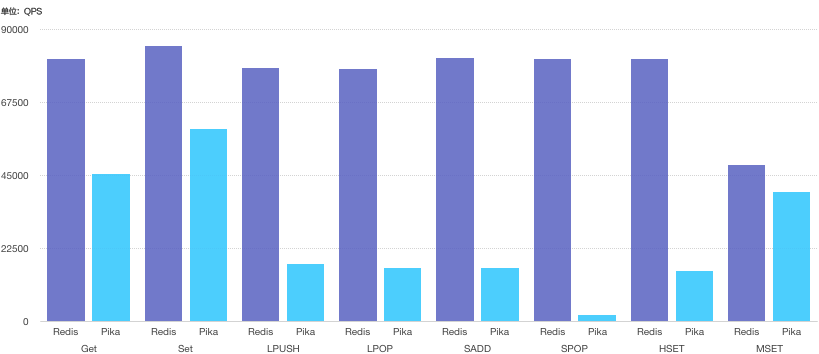
我们还对Pika的单实例与Redis的单实例进行了性能压测对比。
压测命令为redis-benchmark -r 1000000000 -n 1000 -c 50时,性能表现如下:
压测命令为redis-benchmark -r 1000000000 -n 1000 -c 100时,性能表现如下:
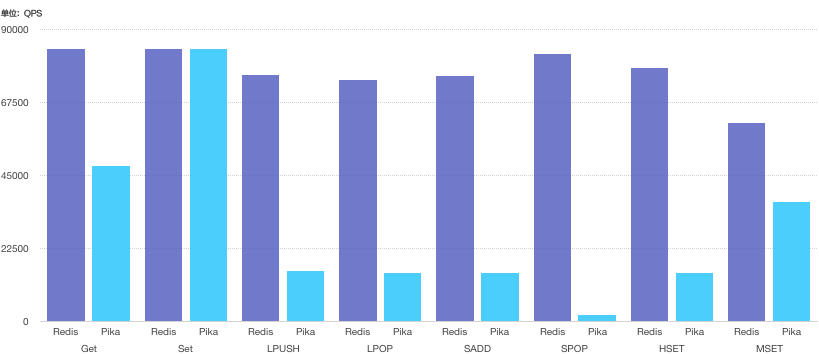
从测试环境的压测结果来看,相对而言,单实例压测情况下,Redis表现占优;使用Pika的场景建议为kv类型性能较好,在五种数据结构里面推荐使用String类型。
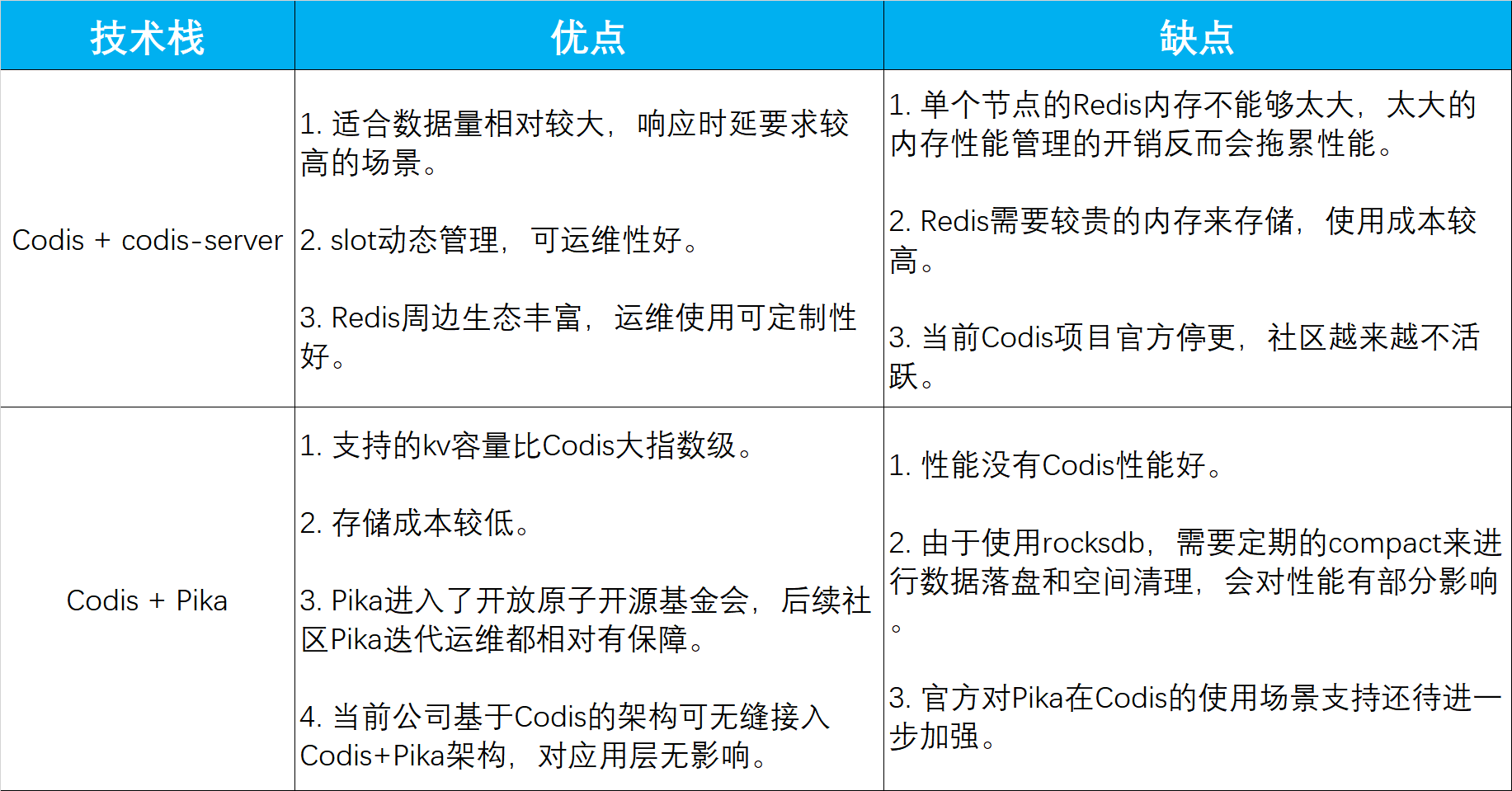
综合压测数据和现网情况,我们对Codis + codis-server和Codis + Pika两种技术栈的优缺点进行了总结:
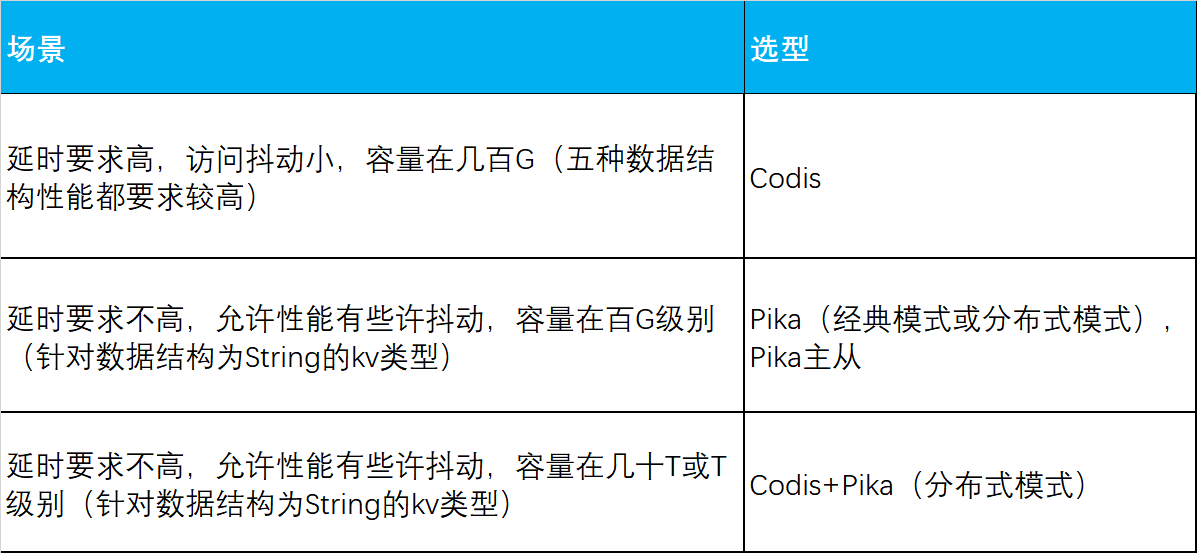
针对如上对比,我们的选型建议如下:
总结
以上是个推使用Pika替换codis-server,以低成本实现海量kv数据存储与读写的实战过程。
个推《大数据降本提效》专栏还将持续关注性能与成本的平衡之道,希望我们的实战经验能帮助大数据从业者们更快地找到大数据降本提效的最优解。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技