开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








个推CTO叶新江:DT时代下[个推3.0]遵循的四个法则
- 品牌动态
 发表于2015年12月30日
发表于2015年12月30日

DT(Data Technology),是以服务大众、激发生产力为主的技术。从IT时代走向DT时代,我们要思考如何用互联网技术、理念、思想去与传统行业进行交融和共同发展。
1、数据是决策的基本依据
在数亿客户端情况下,如何迅速定位?譬如:有的手机定位正常,有的不正常;有的区域定位正常,有的不正常;有的版本定位正常,有的不正常。
而个推的解决方案是,首先是进行意识培养,第二是数据抽样收集以及集中分析。个推团队做了一个叫Logful的开源产品,通过抽样的方法,解决定位问题,同时能极大地降低成本。

Logful SDK架构
2、数据越热越有价值
个推对数据划分为冷数据、温数据、热数据三种类别。冷数据是较长时间之前的状态数据,即用户画像数据;温数据则是非即时的状态和行为数据;而热数据是指即时的位置状态、交易和浏览行为。
移动互联网时代,个推发现用户的兴趣和爱好,会随着一些热点事件、市场营销活动的发生或进展而变化。随之热数据的价值会越来越大,如果一款应用或者大数据平台能够及时地抓住这些热数据并进行处理,也许会发现新的商业机会。
个推应景推送技术能够精准捕捉场景,在合适的地点触发消息,其本质是利用冷数据加上热数据进行实时处理。且个推采用服务端处理的方案,在保证一定可接受的数据量的基础上,很多业务在服务端处理,能把热数据进行非常及时的加工,从而高效充分地把热数据的价值利用起来。
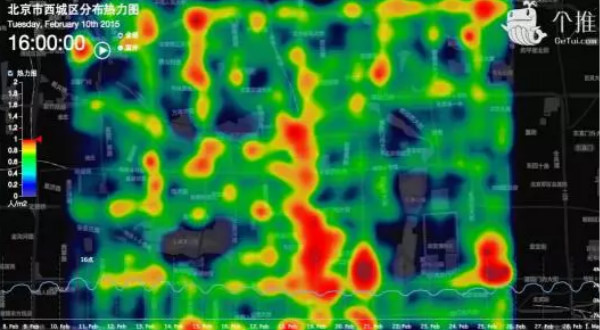
上图是春节期间北京西城区的人口热力图,地图上的色块用于表现该地区的拥挤程度以及人群分布情况,颜色上,红色代表人数密集,橙色次之,蓝色则为稀疏,这是个推对热数据的应用。
3、近似优于精确
考虑以下场景:你需要统计数据流中独立元素的个数? 要求:实时,至少是准实时。但是你面临几个问题:1、数据流速度很快,意味着无法使用二级存储。2、数据规模巨大意味着要么使用超大内存的设备, 要么多个设备分而治之运算,但多大算是个头?
一般数据量大了以后会经常碰见这些问题。如果想得到精确解,代价是非常高昂的,所以能够得到一个问题的近似解则是最优的解决方案。
Flajolet-Martin算法:一个简单直观的基数估算方法
1、随机生成n个服从均匀分布的数字
2、随便重复其中一些数字,重复的数字和重复次数都不确定
3、打乱这些数字的顺序,得到一个数据集
4、永远的墨菲定律
如果有两种或者两种以上的方法去做某件事情,其中一种选择方式将导致灾难,必定有人会做出这种选择。通俗来说就是如果事情有变坏的可能,不管这种可能性有多小,它总会发生。
个推推送服务内部用了很多Redis的产品,特别是Redis 2.8 earlier 版本在网络闪断情况下会遇到很多问题。如果数据量小可能不会造成严重影响,但如果是几十G甚至接近上百G的数据,而且复制过程中又有很多请求访问Redis时,几毫秒会变成几百毫秒、几秒。特别是需要实时处理的时候,流量并不一定会按照预期到来,还有攻击、域名劫持、设备断电等问题,这些都是非常棘手的。
对此,叶总给出的对策是:异常情况分析 + 预案设定 + 沙盘推演 + 模拟操作。
一款APP刚上线,如果该APP很受欢迎,它的流量完全是不规则的,所以不能完全按照预期来设定流量大小。而需要做各个环节的流量控制。个推工程师在很多时候对于很多流量控制、异常的处理都会放在优先级的环境下,提前做这样的需求,强制检查。
产品设计阶段,从技术角度来讲,一定要有对异常情况的分析,所有代码里是否有异常的cache?有没有考虑到断网时长?出现这些问题怎么解决?不要真的等问题出现的时候才想解决方案,而是需要事先进行模拟演练。可以梳理从最开始网络流量进来到交换机、路由器,以及最终的系统等一系列过程,看看哪个环节可能存在异常。有很多问题,当应用规模不是很大的时候,影响也不会很大,但当应用规模大到一定程度,则会是特别严重的问题。所以异常情况分析 + 预案设定 + 沙盘推演 + 模拟操作是很有必要的。
以上内容来自个推CTO叶新江在ArchSummit全球架构师峰会北京站,基础架构之技术演进专场的分享整理,希望能带给广大创业者一些启发。


 推荐文章
推荐文章
 关注我们
关注我们