开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








个推技术学院:手把手教你用TensorFlow构建图书识别模型
- 大数据
 发表于2020年4月26日
发表于2020年4月26日

前几天是世界读书日,相信很多小伙伴嘴上说着学不动了,身体还是很诚实的。毕竟读书还是有很多好处的,比如能让你的脑门散发智慧的光芒。为此,个推也为大家准备了超豪华读书大礼包,帮助大家遇见更好的自己。
【文末有活动哦】
今天的主题不仅仅是送图书,我们也想要借助这个特殊的机会,普及一下Tensorflow相关的知识,并教大家做一个简单易上手的图书识别模型。
正文:
什么是迁移学习
以图书识别模型训练为例,迁移学习指的是我们利用前人训练好的具备图片识别能力的AI模型,在保留AI模型对图片特征提取能力的基础上再训练,使AI模型具备识别图书的能力。迁移学习能够大大提高模型训练的速度,并达到相对不错的正确率。
今天我们会基于SSD Mobile Net V1模型,进行迁移学习。初次接触神经网络的同学可以将其理解为一种具备图片识别能力的轻便小巧的AI模型,它能够在移动设备上高效地运行。我们在SSD Mobile Net模型基础上去设计一个AI模型,并让它在Vue Application中运行,使网页能够识别并圈选出图片中相应的目标对象。
准备工作
同步开发环境
为了避免大家因为环境问题遇到各种各样的坑,运行环境尽量保持一致。
开发环境
系统:Mac OS系统;Python版本:3.7.3;TensorFlow版本:1.15.2;TensorFlowJS版本:1.7.2;开发工具:Pycharm和Webstorm
下载项目
同步完开发环境后,终于要开始动工了。首先我们需要在Github上下载几个项目:
准备图片素材
首先, 我们可以通过搜索引擎收集有关图书的图片素材:
其次,我们可以在Github上克隆LabelImg项目,并根据Github的使用说明,按照不同的环境安装运行LabelImg项目,运行后的页面如下:
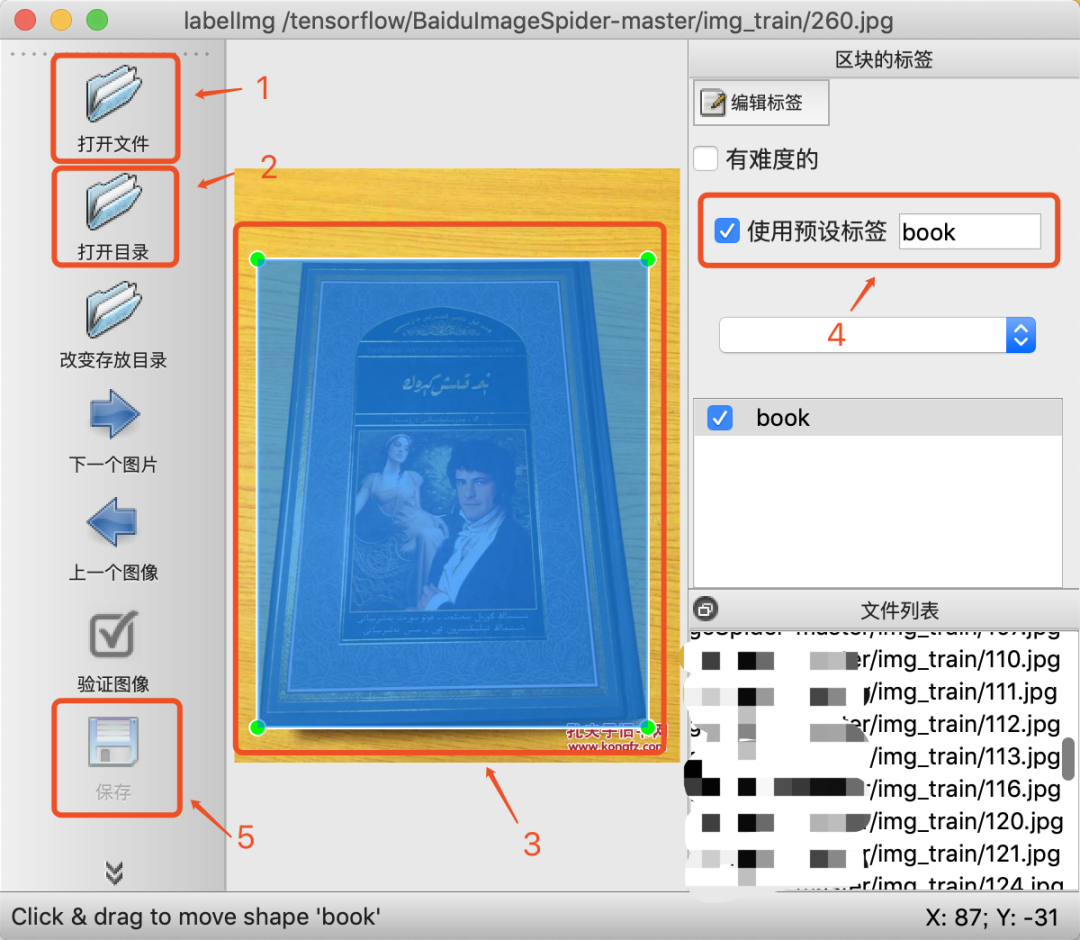
然后,按照以下步骤,将图片格式转换为圈选区域后的XML格式文件:
第一步,打开图片存放的目录;第二步,选择圈选后的存放目录;第三步,圈选图片目标区域;第四步,设置圈选区域的标签;第五步,保存成XML格式。
操作完成后,我们在存放的目录下会看到许多XML格式的文件,这个文件记录了图片的位置信息、圈选信息和标签信息等,用于后续的模型训练。
配置安装Object Detection的环境
我们从Github克隆迁移模型训练的项目【 https://github.com/tensorflow/models/tree/r1.5】。注意要在r1.5分支运行,并用PyCharm打开项目。
首先下载TensorFlow1.15.2版本:
pip install tensorflow==1.15.2
其次安装依赖包。
然后通过终端切换到research目录,并执行几行配置命令,具体请参考Github的使用说明:https://github.com/DaMaiGit/raccoon_dataset。
最后运行model_builder_test.py文件,如果在终端中看到OK字样,则表示配置成功。
python object_detection/builders/model_builder_test.py
将XML格式转换为TensorFlow需要的TFRecord格式
克隆并打开图片格式转换项目,然后对该项目加以小改造:
改造文件目录:
- 删除annotations、data、training目录中的内容
- 在raccoon_dataset下增加一个xmls目录,用以存放xml文件
改造文件:
接着,我们再改造以下两个文件并新增一个文件,方便我们转换图片格式
1.改造xml_to_csv.py(具体修改逻辑参照Github库)。
2.改造generate_tfrecord.py文件,将csv格式转换为TensorFlow需要的record格式:
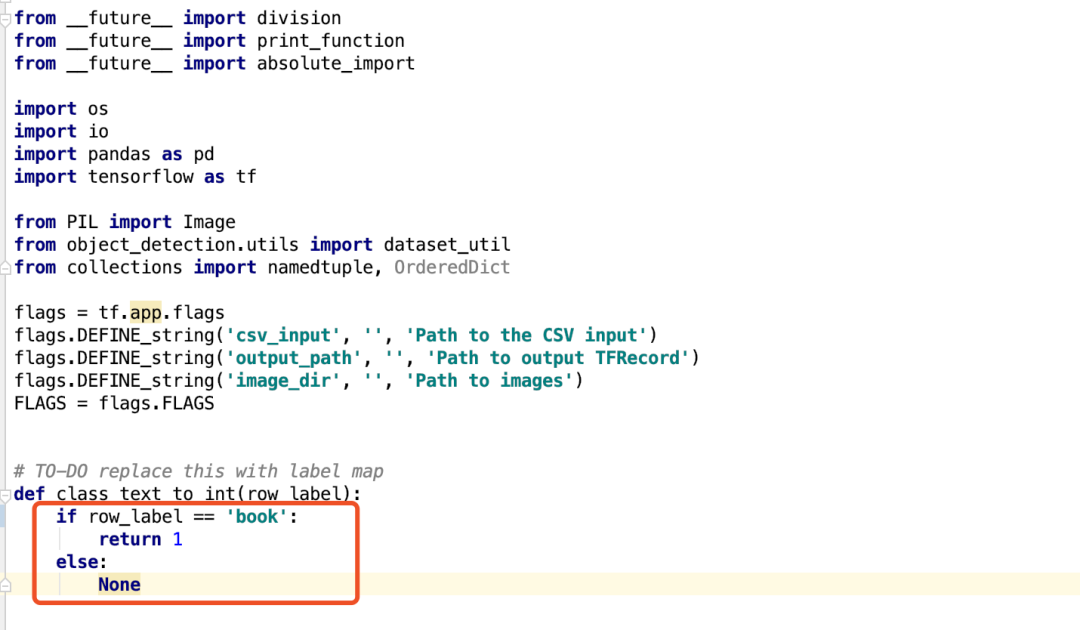
将该区域的row_label改成LabelImg中的标签名,因为我们只有一个标签,所以直接修改成book即可。
3.新增一个generate_tfrecord.sh脚本,方便执行generate_tfrecord.py文件
配置Object Decation的环境:
export PYTHONPATH=$PYTHONPATH:你的models/research/slim所在的全目录路径
最后将图片文件复制到images目录,将xml格式文件复制到xmls目录下,再执行xml_to_csv.py文件,我们会看到data目录下产生了几个csv格式结尾的文件。这时,我们在终端执行generate_tfrecord.sh文件,TensorFlow所需要的数据格式就大功告成啦。
迁移训练模型:
在这个环节要完成以下三步:
一是将刚刚生成好的record文件放到对应目录下;二是下载SSD Mobile Net V1模型文件;三是配置book.pbtxt文件和book.config文件。
放置record文件和SSD Mobile Net V1模型
为了操作方便,我们直接将models/research/object_detection/test_data下的目录清空,放置迁移训练的文件。
首先通过Tensorflow detection model zoo 网页下载SSD Mobile Net V1模型文件:
下载第一个ssdmobilenetv1coco模型即可,下载完毕后,对文件进行解压,将模型相关的文件放在`testdata的model目录下,并将我们刚刚生成的record文件放置在test_data`目录下。
完成pbtxt和config配置文件
我们在test_data目录下,新建一个book.pbtxt文件,并完成配置内容。我们只有一个标签,因此直接配置一个id值为1,name为book的item对象即可。
item {
id: 1
name: 'book'
}
由于我们使用SSD Mobile Net V1模型进行迁移学习,因此我们到sample\configs目录下复制一份ssd_mobilenet_v1_coco.config文件并重命名为book.config文件。
接着,我们修改book.config中的配置文件,将num_classes修改为当前的标签数量。由于我们只有一个book标签,因此修改成1即可。
然后,修改所有PATH_TO_BE_CONFIGURED的路径:
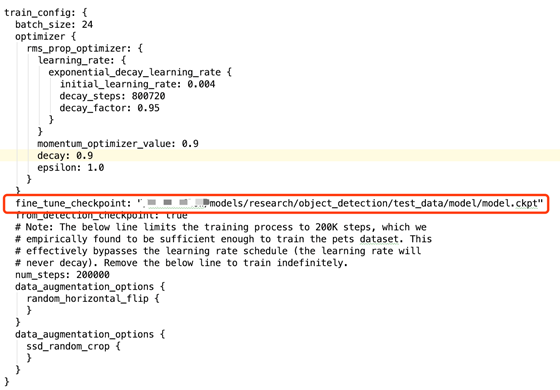
将模型文件地址设置成testdata/model/model.ckpt的全路径地址。
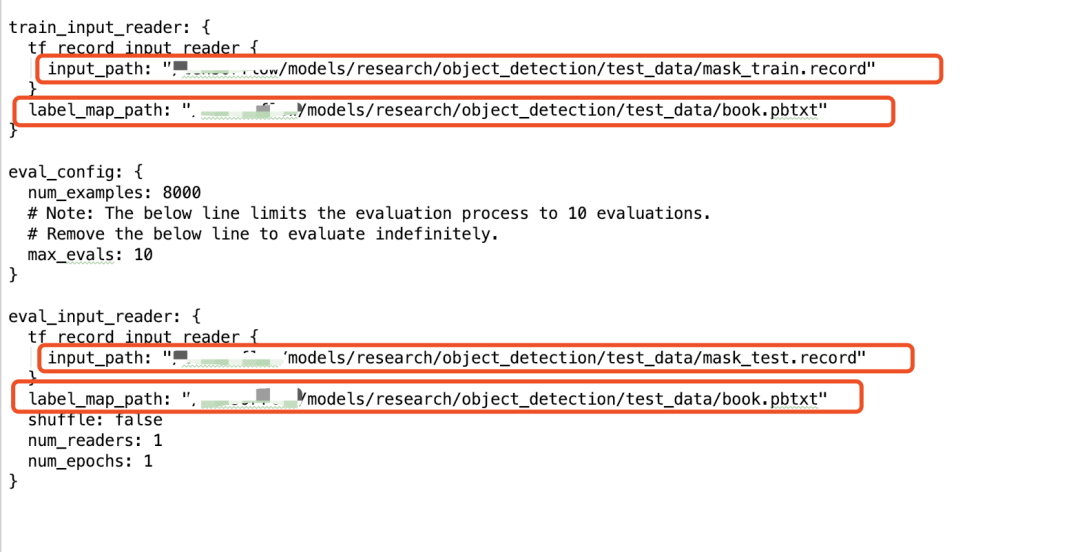
将train_input_reader的input_path设置成mask_train.record的全路径地址;将label_map_path设置成book.pbtxt的全路径地址;将eval_input_reader的input_path设置成mask_test.record的全路径地址。
到目前为止我们所有配置都已经完成啦。接下来我们开始训练模型。
运行train.py文件训练模型
在终端中运行train.py文件,开始迁移学习、训练模型。
python3 train.py --logtostderr --train_dir=./test_data/training/ --pipeline_config_path=./test_data/book.config
其中train_dir为训练后的模型存放的目录,pipelineconfigpath为book.config文件所在的相对路径。
运行命令后,我们可以看到模型在进行一步一步地训练,并会在/test_data/training目录下存放训练后的模型文件。
将ckpt文件转换为pb文件
通过export_inference_graph.py文件,将训练好的模型转换为pb格式的文件,这个文件格式在后面要用来转换为TensorFlow.js能够识别的文件格式。
我们在执行命令时,需要运行export_inference_graph.py文件:
其中pipeline_config_path为book.config的相对文件路径,trained_checkpoint_prefix为模型文件的路径,例如我们选择训练了1989步的模型文件,output_directory为我们输出pb文件的目标目录。
运行完后,我们可以看到一个新生成的book_model_test目录。在这个目录下,我们成功将ckpt格式转换成了pb格式。
将pb文件转换为TensorFlowJs模型
首先,我们需要依赖TensorFlowjs的依赖包
pip install tensorflowjs
然后,通过命令行转换刚刚生成的pb文件。在这一步骤中,我们需要设置最后两个参数,即saved_model的目录与TensorFlow.js识别模型的输出目录。
运行结束后,可以看到一个新生成的web_model目录,内含迁移学习训练后的模型。
到这里,模型训练的阶段终于结束了。
在Vue中运行模型
准备工作
新建Vue项目,在Vue项目的public目录下放入我们训练好的模型,即web_model整个目录。
接着借助Tensorflow.js的依赖包,在package.json的dependencies中加入:
"@tensorflow/tfjs": "^1.7.2",
"@tensorflow/tfjs-core": "^1.7.2",
"@tensorflow/tfjs-node": "^1.7.2",
然后通过npm命令安装依赖包。
加载模型
在JS代码部分引入TensorFlow的依赖包:
import * as tf from '@tensorflow/tfjs';
import {loadGraphModel} from '@tensorflow/tfjs-converter';
接着第一步,我们先加载模型文件中的model.json文件:
const MODEL_URL = process.env.BASE_URL+"web_model/model.json";
this.model = await loadGraphModel(MODEL_URL);
通过loadGraphModel方法,加载好训练的模型,再将模型对象打印出来:
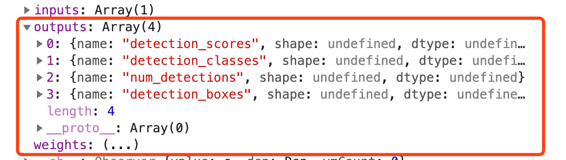
image-20200421132921380
随后可以看到模型会输出一个长度为4的数组:
detection_scores:表示识别对象模型的置信度,置信度越高,则代表模型认为对应区域识别为书本的可能性越高
detection_classes:表示模型识别的区域对应的标签,例如在本案例中,识别出来的是book
num_detections:表示模型识别出目标对象的个数
detection_boxes:表示模型识别出来目标对象的区域,为一个长度为4的数组,分别是:[xpos,ypos,xwidth,yheight] 。第一个位代表圈选区域左上角的x坐标,第二位代表圈选左上角的y坐标,第三位代表圈选区域的宽度,第四位代表圈选区域的长度。
模型识别
知道了输出值,我们就可以将图片输入到模型中,得到模型预测的结果:
const img = document.getElementById('img');
let modelres =await this.model.executeAsync(tf.browser.fromPixels(img).expandDims(0));
通过model.executeAsync方法,将图片输入到模型中,从而得到模型的输出值,其结果是前文提到的一个长度为4的数组;接着通过自定义方法,将得到的结果进行整理,从而输出一个想要的结果格式:
通过调用buildDetectedObjects来整理和返回最后的结果:
detection_scores:表示识别对象模型的置信度,置信度越高,则代表模型认为对应区域识别为书本的可能性越高
detection_classes:表示模型识别的区域对应的标签,例如在本案例中,识别出来的是book
num_detections:表示模型识别出目标对象的个数
detection_boxes:表示模型识别出来目标对象的区域,为一个长度为4的数组,分别是:[xpos,ypos,xwidth,yheight] 。第一个位代表圈选区域左上角的x坐标,第二位代表圈选左上角的y坐标,第三位代表圈选区域的宽度,第四位代表圈选区域的长度。
调用buildDetectedObjects方法。
通过modelres[0].dataSync(),来获取对应结果的数组对象,再输入到方法中,从而最终获得res结果对象:

最后我们通过Canvas的API,将图片根据bbox返回的数组对象,画出对应的区域即可。最终效果如下:

项目体验地址:http://at.iunitv.cn/
最后
模型训练具有一定的局限性,其效果与训练时间及图片复杂度相关。本文旨在为大家普及TensorFlow.js相关知识并提供一种简便、易于上手的AI案例。各位小伙伴在模型训练过程中可以根据需要对其进行优化。
世界读书日,我们希望和广大程序员一起学习新知、共同进步,个推技术学院也特地为大家准备了豪华读书大礼包,愿每位热爱学习的开发者都能畅游知识的海洋,遇见更好的自己!
活动奖品:
一等奖:极客时间充值卡1张,1名

二等奖:得到电子书年度会员1张,3名

三等奖:《深度学习》1本,5名

抽奖方式:
扫描下方二维码关注个推技术学院公众号,后台回复“我爱读书”获取抽奖入口,点击即可参与抽奖。

开奖时间:2020年4月27日 16:00,系统将随机抽取出幸运粉丝。
领取方式:请中奖者于24小时内在抽奖助手中填写收件信息,我们会在7个工作日之内为您寄出奖品。
注:活动解释权归个推所有。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技