开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








深入浅出Hive数据倾斜
- 数据智能
- 大数据
 发表于2021年1月4日
发表于2021年1月4日
引言
我们日常使用HSQL的时候经常会遇到这样一个令人苦恼的场景:执行一个非常简单的SQL语句,任务的进度条长时间卡在99%,不确定还需多久才能结束,这种现象称之为数据倾斜。这一现象经常出现的原因在于分析师主要关注分析逻辑和数据结果的正确性,却很少关注SQL语句的执行过程与效率。
在处理海量数据的实践中,个推分析师需要解决各种困难,以高效、准确地使用SQL语句进行数据处理,在此过程中,也积累了丰厚的实战经验。本文将为你深入浅出地讲解Hive数据倾斜的原因以及解决的方法,从而帮你快速完成工作!
什么是数据倾斜
数据倾斜在MapReduce计算框架中经常发生。通俗理解,该现象指的是在整个计算过程中,大量相同的key被分配到了同一个任务上,造成“一个人累死、其他人闲死”的状况,这违背了分布式计算的初衷,使得整体的执行效率十分低下。
MapReduce原理
Hive的底层计算模型和框架是MapReduce。我们只有理解了MapReduce的工作原理,才能更好地对HSQL进行优化,写出高效的查询语句。
下图是 MapReduce 原理图。
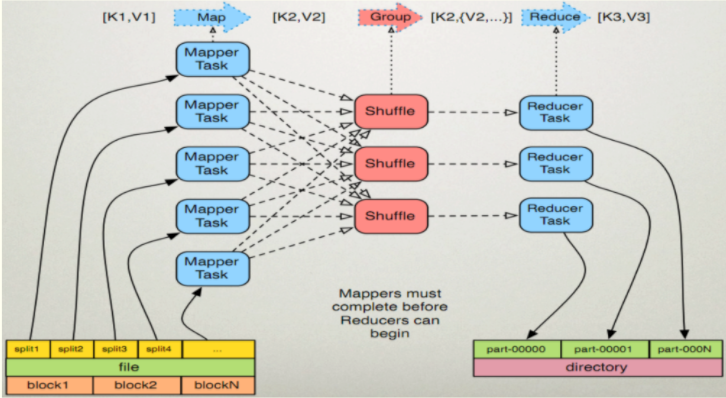
我们通过对以下三条数据中的单词进行计数,来解释整个MapReduce的执行过程。
hive|spark|hive|hbase
hadoop|hive|spark|hive
sqoop|flume|scala|scala
具体步骤如下:
1、Map任务处理
1.1 MapReduce读取HDFS中的文件并进行切割,将每一行解析成一个<k,v>(初始的k值是根据偏移量来的)。
(0,"hive spark hive hbase")
(21,"hadoop hive
spark hive")
(39,"sqoop flume scala scala")
1.2 Map任务将1.1产生的 <k,v>值转换为新的<k,v>值,并将这个结果存入环形缓冲内存中(溢出的部分存入磁盘),具体数据如下:
(hive,1),(spark,1),(hive,1),(hbase,1);
(hadoop,1),(hive,1),(spark,1),
(hive,1);
(sqoop,1),(flume,1),(scala,1), (scala,1);
1.3 Map任务将不同分区中的数据进行排序、分组,相同的 k 放到同一个集合中(溢出部分的数据存入本地磁盘),结果如下:
(hive,[1,1,1,1]),(spark,[1,1]),(hbase,[1]),(hadoop,[1]),(sqoop,[1]),(flume,[1]),(scala,[1,1])
1.4 Map任务对分组后的数据进行归约(可选)。
2、Reduce任务处理
2.1 Reduce任务先处理多个Map任务的输出结果,再根据分区将其分配到不同的Reduce节点上(这个过程就是shuffle);
2.2 Reduce任务对多个Map的输出结果进行合并、排序、计算,生成新的 (k,v) 值,具体如下:
(hive,4),(spark,2), (scala,2) ,(hbase,1),(hadoop,1),(sqoop,1),(flume,1)
2.3 Reduce任务会将上一步输出的<k,v>写到HDFS中,生成文件。
数据倾斜解决方案
通过上面的介绍,相信大家已经了解了MapReduce的解析原理。日常工作中数据倾斜主要发生在Reduce阶段,而很少发生在 Map阶段,其原因是Map端的数据倾斜一般是由于HDFS数据存储不均匀造成的(公司的日志存储几乎都是均匀分块存储,每个文件大小基本固定),而Reduce阶段的数据倾斜几乎都是因为分析师没有考虑到某种key值数据量偏多的情况而导致的。
Reduce阶段最容易出现数据倾斜的两个场景分别是Join和Count Distinct。有些博客和文档将Group By也纳入其中,但是我们认为如果不使用Distinct,仅仅对分组数据进行Sum和Count操作,并不会出现数据倾斜。如果发生数据倾斜,我们首先需要调整参数,再进行负载均衡处理:
set hive.map.aggr=true;(默认为ture)
(map端的Combiner )
set hive.groupby.skewindata=true (默认为false)
解决数据倾斜首先要进行负载均衡操作,将上面两个参数设定为 true,而MapReduce进程则会生成两个额外的 MR Job,这两个任务的主要操作如下:
操作步骤
第一步:MR Job 中Map 输出的结果集合首先会随机分配到 Reduce 中,然后每个 Reduce 做局部聚合操作并输出结果,这样处理的原因是相同的Group By Key有可能被分发到不同的 Reduce Job中,从而达到负载均衡的目的。
第二步:MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成聚合操作。
在设置好这两个参数之后,我们仍然需要针对不同的SQL语句进行SQL优化,主要分为两个场景, join操作发生的数据倾斜以及Count Distinct操作带来的数据倾斜。
场景一:Join
方案一:使用Mapjoin进行关联
Mapjoin会将小表的全量数据加载到内存中,使Join操作提前到 Map 端进行,避免某个过多的key分发到同一个Reduce Job中。这个过程不会经历Shuffle阶段和Reduce阶段,直接由Map端输出结果文件。大表中的数据作为Map的输入,Map()函数对输入的每一对<k,v>值都能够方便地和已加载到内存中的小表数据进行连接(使用mapjoin的前提条件是确保内存能够存入小表的全量数据)。
以下2个参数控制Mapjoin的使用:
set hive.auto.convert.join= ture; 设置自动化开启(默认为false)
hive.mapjoin.smalltable.filesize=25000000; 设置小表大小的上限(默认为25M)
执行Mapjoin 操作,具体语句如下:

方案二:将小表放入子查询
小表的查询结果相当于大表的一个where条件(需要注意的是小表的输出结果不能太大)。

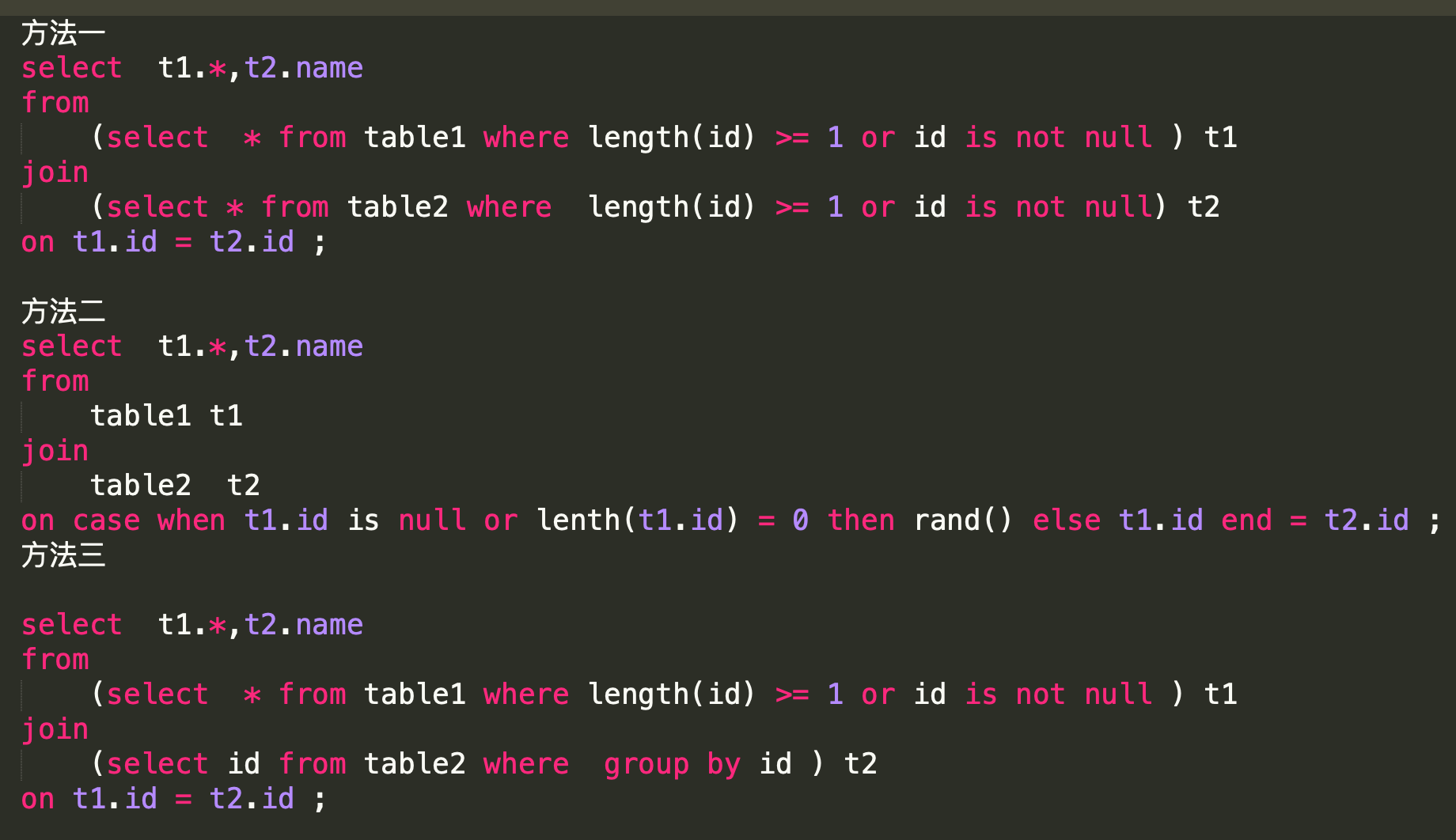
方案三:关联字段去重
很多时候发生数据倾斜是因为两表的关联字段有大量的重复值(大量Null也是一种情况),这个时候只要确保其中一个表关联字段值唯一即可。具体做法可以参考如下三种。
场景二:Count Distinct
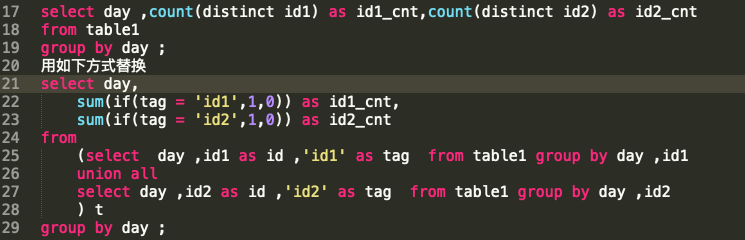
由于SQL中的Distinct操作本身会有一个全局排序的过程,一般情况下,不建议采用Count Distinct方式进行去重计数,除非表的数量比较小。当SQL中不存在分组字段时,Count Distinct操作仅生成一个Reduce 任务,该任务会对全部数据进行去重统计;当SQL中存在分组字段时,可能某些Reduce 任务需要去重统计的数量非常大。在这种情况下,我们可以通过以下方式替换:
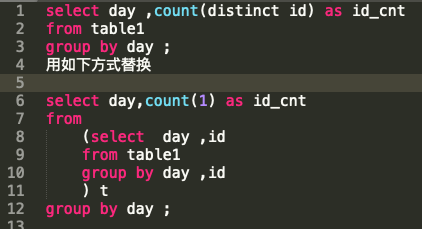
如果语句中存在多个Distinct命令,开发者需要评估下用空间换时间的方法是否能够提升效率,具体的评估语法如下:
总结
上文讲解了Hive数据倾斜发生的原因、解决方案以及两种主要场景下的具体做法。概括而言,让Map端的输出数据更均匀地分布到Reduce中,是我们的终极目标,也是解决Reduce端倾斜的必然途径。在此过程中,掌握四点可以帮助我们更好地解决数据倾斜问题。
1、如果任务长时间卡在99%则基本可以认为是发生了数据倾斜,建议开发者调整参数以实现负载均衡:set hive.groupby.skewindata=true;
2、小表关联大表操作,需要先看能否使用子查询,再看能否使用Mapjoin;
3、Join操作注意关联字段不能出现大量的重复值或者空值;
4、Count(distinct id ) 去重统计要慎用,尽量通过其他方式替换。
最后,期待每一位看到这篇文章的小伙伴们都能有一定的收获,并且能够快速地解决Hive中的数据倾斜问题。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技