开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








基于机器学习的异常值检测
- 智能风控
- 数据智能
 发表于2021年2月20日
发表于2021年2月20日
异常值检测与告警一直是工业界非常关注的问题,自动准确地检测出系统的异常值,不仅可以节约大量的人力物力,还能尽早发现系统的异常情况,挽回不必要的损失。个推也非常重视大数据中的异常值检测,例如在运维部门的流量管理业务中,个推很早便展开了对异常值检测的实践,也因此积累了较为丰富的经验。本文将从以下几个方面介绍异常值检测。
- 异常值检测研究背景
- 异常值检测方法原理
- 异常值检测应用实践
异常值检测研究背景
异常值,故名思议就是不同于正常值的值。在数学上,可以用离群点来表述,这样便可以将异常值检测问题转化为数学问题来求解。
异常值检测在很多场景都有广泛的应用,比如:
- 流量监测
互联网上某些服务器的访问量,可能具有周期性或趋势性:一般情况下都是相对平稳的,但是当受到某些黑客攻击后,其访问量可能发生显著的变化,及早发现这些异常变化对企业而言有着很好的预防告警作用。
- 金融诈骗
正常账户中,用户的转账行为一般属于低频事件,但在某些金融诈骗案中,一些嫌犯的账户就可能会出现高频的转账行为,异常检测系统如果能发现这些异常行为,及时采取相关措施,则会规避不少损失。
- 机器故障检测
一个运行中的流水线,可能会装有不同的传感器用来监测运行中的机器,这些传感器数据就反应了机器运行的状态,这些实时的监测数据具有数据量大、维度广的特点,用人工盯着看的话成本会非常高,高效的自动异常检测算法将能很好地解决这一问题。
异常值检测方法原理
本文主要将异常值检测方法分为两大类:一类是基于统计的异常值检测,另一类是基于模型的异常值检测。
基于统计的方法
基于模型的方法
- 基于统计的异常值检测方法
常见的基于统计的异常值检测方法有以下2种,一种是基于3σ法则,一种是基于箱体图。
3σ法则
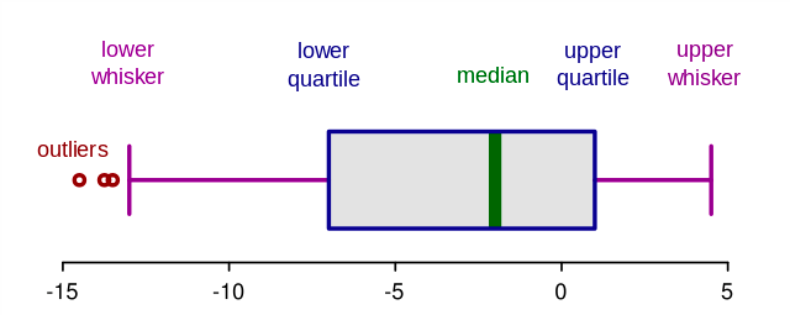
箱体图
3σ法则是指在样本服从正态分布时,一般可认为小于μ-3σ或者大于μ+3σ的样本值为异常样本,其中μ为样本均值,σ为样本标准差。在实际使用中,我们虽然不知道样本的真实分布,但只要真实分布与正太分布相差不是太大,该
箱体图也是一种比较常见的异常值检测方法,一般取所有样本的25%分位点Q1和75%分位点Q3,两者之间的距离为箱体的长度IQR,可认为小于Q1-1.5IQR或者大于Q3+1.5IQR的样本值为异常样本。
基于统计的异常检测往往具有计算简单、有坚实的统计学基础等特点,但缺点也非常明显,例如需要大量的样本数据进行统计,难以对高维样本数据进行异常值检测等。
- 基于模型的异常值检测
通常可将异常值检测看作是一个二分类问题,即将所有样本分为正常样本和异常样本,但这和常规的二分类问题又有所区别,常规的二分类一般要求正负样本是均衡的,如果正负样本不均匀的话,训练结果往往会不太好。但在异常值检测问题中,往往面临着正(正常值)负(异常值)样本不均匀的问题,异常值通常比正常值要少得多,因此需要对常规的二分类模型做一些改进。
基于模型的异常值检测一般可分为有监督模型异常值检测和无监督模型异常值检测,比较典型的有监督模型如oneclassSVM、基于神经网络的自编码器等。oneclassSVM就是在经典的SVM基础上改进而来,它用一个超球面替代了超平面,超球面以内的值为正常值,超球面以外的值为异常值。
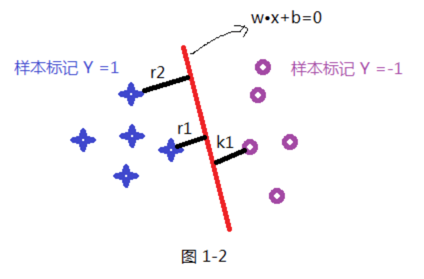
经典的SVM
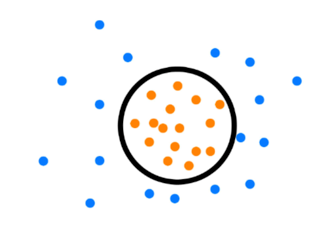
oneclassSVM
基于神经网络的自编码器结构如下图所示。
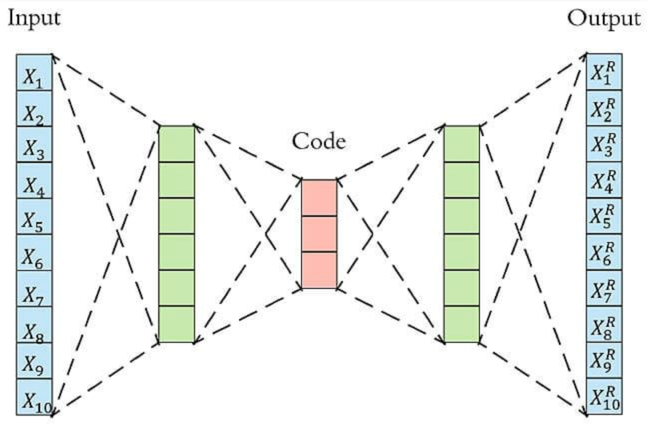
自编码器(AE)
将正常样本用于模型训练,输入与输出之间的损失函数可采用常见的均方误差,因此检测过程中,当正常样本输入时,均方误差会较小,当异常样本输入时,均方误差会较大,设置合适的阈值便可将异常样本检测出来。但该方法也有缺点,就是对于训练样本比较相近的正常样本判别较好,但若正常样本与训练样本相差较大,则可能会导致模型误判。
无监督模型的异常值检测是异常值检测中的主流方法,因为异常值的标注成本往往较高,另外异常值的产生往往无法预料,因此有些异常值可能在过去的样本中根本没有出现过,这将导致某些异常样本无法标注,这也是有监督模型的局限性所在。较为常见的无监督异常值检测模型有密度聚类(DBSCAN)、IsolationForest(IF)、RadomCutForest(RCF)等,其中DBSCAN是一种典型的无监督聚类方法,对某些类型的异常值检测也能起到不错的效果。该算法原理网上资料较多,本文不作详细介绍。
IF算法最早由南京大学人工智能学院院长周志华提出,是一种非常高效的异常值检测方法,该方法不需要对样本数据做任何先验的假设,只需基于这样一个事实——异常值只是少数,并且它们具有与正常值非常不同的属性值。与随机森林由大量决策树组成一样,IsolationForest也由大量的树组成。IsolationForest中的树叫isolation tree,简称iTree。iTree树和决策树不太一样,其构建过程也比决策树简单,因为其中就是一个完全随机的过程。
假设数据集有N条数据,构建一颗iTree时,从N条数据中均匀抽样(一般是无放回抽样)出ψ个样本出来,作为这颗树的训练样本。
在样本中,随机选一个特征,并在这个特征的所有值范围内(最小值与最大值之间)随机选一个值,对样本进行二叉划分,将样本中小于该值的划分到节点的左边,大于等于该值的划分到节点的右边。
这样得到了一个分裂条件和左、右两边的数据集,然后分别在左右两边的数据集上重复上面的过程,直至达到终止条件。终止条件有两个,一个是数据本身不可再分(只包括一个样本,或者全部样本相同),另外一个是树的高度达到log2(ψ)。不同于决策树,iTree在算法里面已经限制了树的高度。不限制虽然也可行,但出于效率考虑,算法一般要求高度达到log2(ψ)深度即可。
把所有的iTree树构建好了,就可以对测试数据进行预测了。预测的过程就是把测试数据在iTree树上沿对应的条件分支往下走,直到达到叶子节点,并记录这过程中经过的路径长度h(x),即从根节点,穿过中间的节点,最后到达叶子节点,所走过的边的数量(path length)。最后计算每条待测数据的异常分数s(Anomaly Score)。异常分数s具有如下性质:
1)如果分数s越接近1,则该样本是异常值的可能性越高;
2)如果分数s越接近0,则该样本是正常值的可能性越高;
RCF算法与IF算法思想上是比较类似的,前者可以看成是在IF算法上做了一些改进。针对IF算法中没有考虑到的时间序列因素,RCF算法考虑了该因素,并且在数据样本采样策略上作出了一些改进,使得异常值检测相对IF算法变得更加准确和高效,并能更好地应用于流式数据检测。
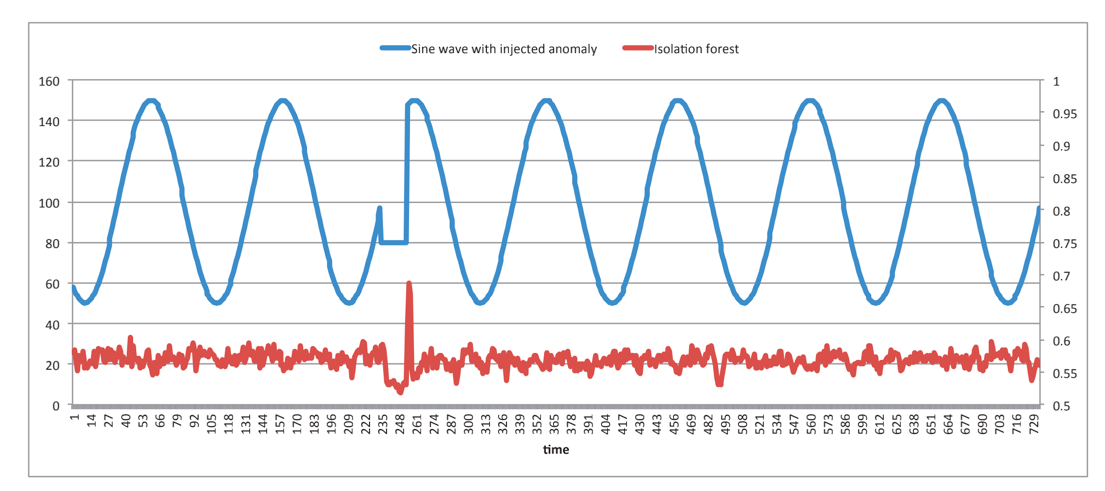
IF算法

RCF算法
上图展示了IF算法和RCF算法对于异常值检测的异同。我们可以看出原始数据中有两个突变异常数据值,对于后一个较大的突变异常值,IF算法和RCF算法都检测了出来,但对于前一个较小的突变异常值,IF算法没有检测出来,而RCF算法依然检测了出来,这意味着RCF有更好的异常值检测性能。
异常值检测应用实践
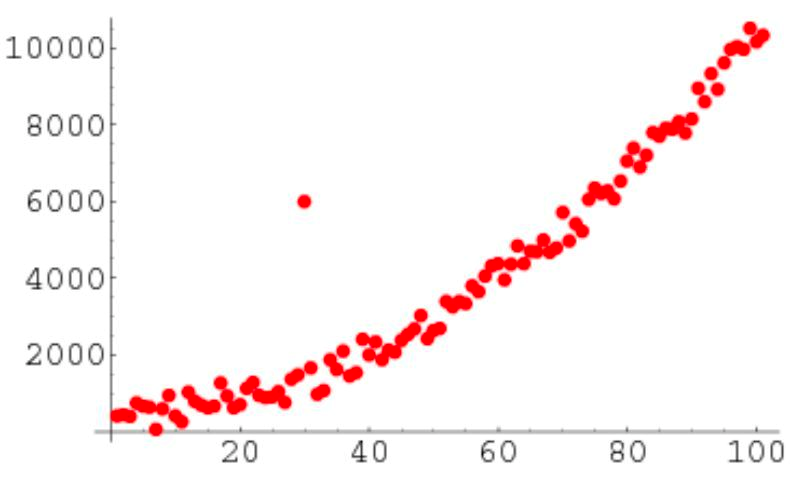
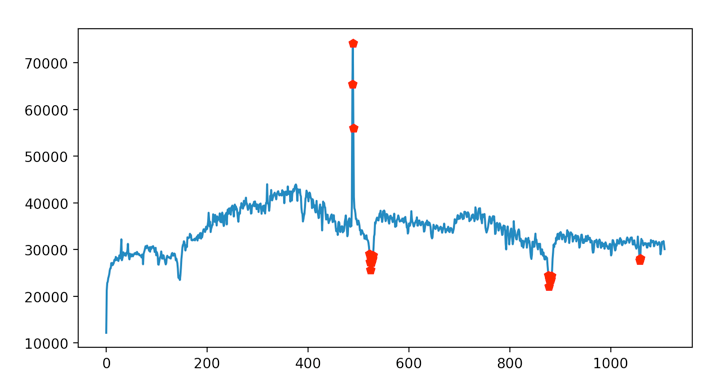
理论还需结合实践,下面我们将以某应用从2016.08.16至2019.09.21的日活变化情况为例,对异常值检测的实际应用场景予以介绍:
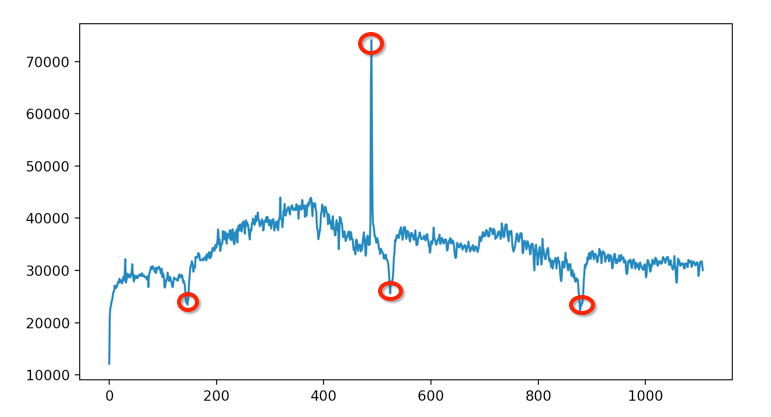
从上图中可以看出该应用的日活存在着一些显著的异常值(比如红色圆圈部分),这些异常值可能由于活动促销或者更新迭代出现bug导致日活出现了比较明显的波动。下面分别用基于统计的方法和基于模型的方法对该日活序列数据进行异常值检测。

基于3σ法则(基于统计)
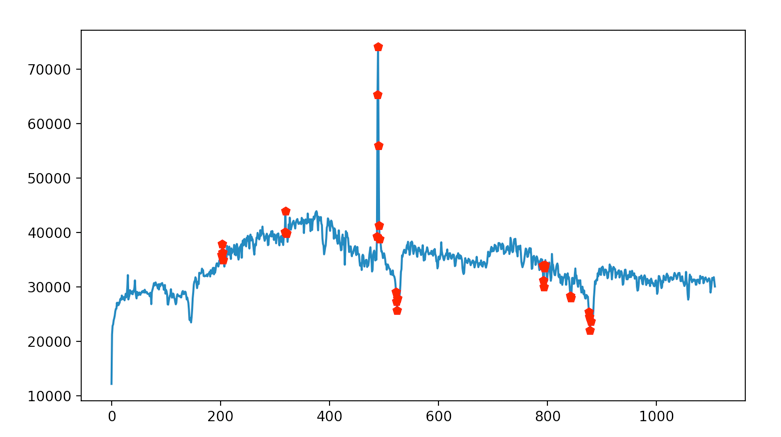
RCF算法(基于模型)
从图中可以看出,对于较大的突变异常值,3σ法则和RCF算法都能较好地检测出来,但对于较小的突变异常值,RCF算法则要表现得更好。
总结
上文为大家讲解了异常值检测的方法原理以及应用实践。综合来看,异常值检测算法多种多样,每一种都有自己的优缺点和适用范围,很难直接判断哪一种异常检测算法是最佳的,具体在实战中,我们需要根据自身业务的特点,比如对计算量的要求、对异常值的容忍度等,选择合适的异常值检测算法。
接下来,个推也会结合自身实践,在大数据异常检测方面不断深耕,继续优化算法模型在不同业务场景中的性能,持续为开发者们分享前沿的理念与最新的实践方案。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技