开发者工具
开发者工具


 运营增长
运营增长
 数据洞察
数据洞察
 AI提效
AI提效

 通用解决方案
通用解决方案
 行业解决方案
行业解决方案








个推技术干货 | 看完这篇,即刻上手进行联邦学习实战
- 品牌营销
- 数据智能
- 大数据
 发表于2021年2月26日
发表于2021年2月26日
一、引言
在数据智能时代,重视数据安全,促进大数据行业健康发展已经成为了全球趋势,但与此同时,企业之间数据孤岛的问题也越来越严重。如何有效打破数据孤岛,进行跨组织的数据价值挖掘,是困扰数据智能行业从业者的一大难题。而“联邦学习”将成为解决这一行业性难题的关键技术。
个推作为专业的数据智能企业,基于多年的经验,不断开展数据应用方面的创新实践。联邦学习正是个推开展这一实践的重要技术支撑。
本文将从联邦学习的定义、分类体系以及建模实践等几个方面展开。
二、联邦学习介绍
-
联邦学习的定义
联邦学习(Federated machine learning)是一个机器学习框架,能有效帮助多个机构在保护数据安全的前提下,进行数据使用和机器学习建模。
-
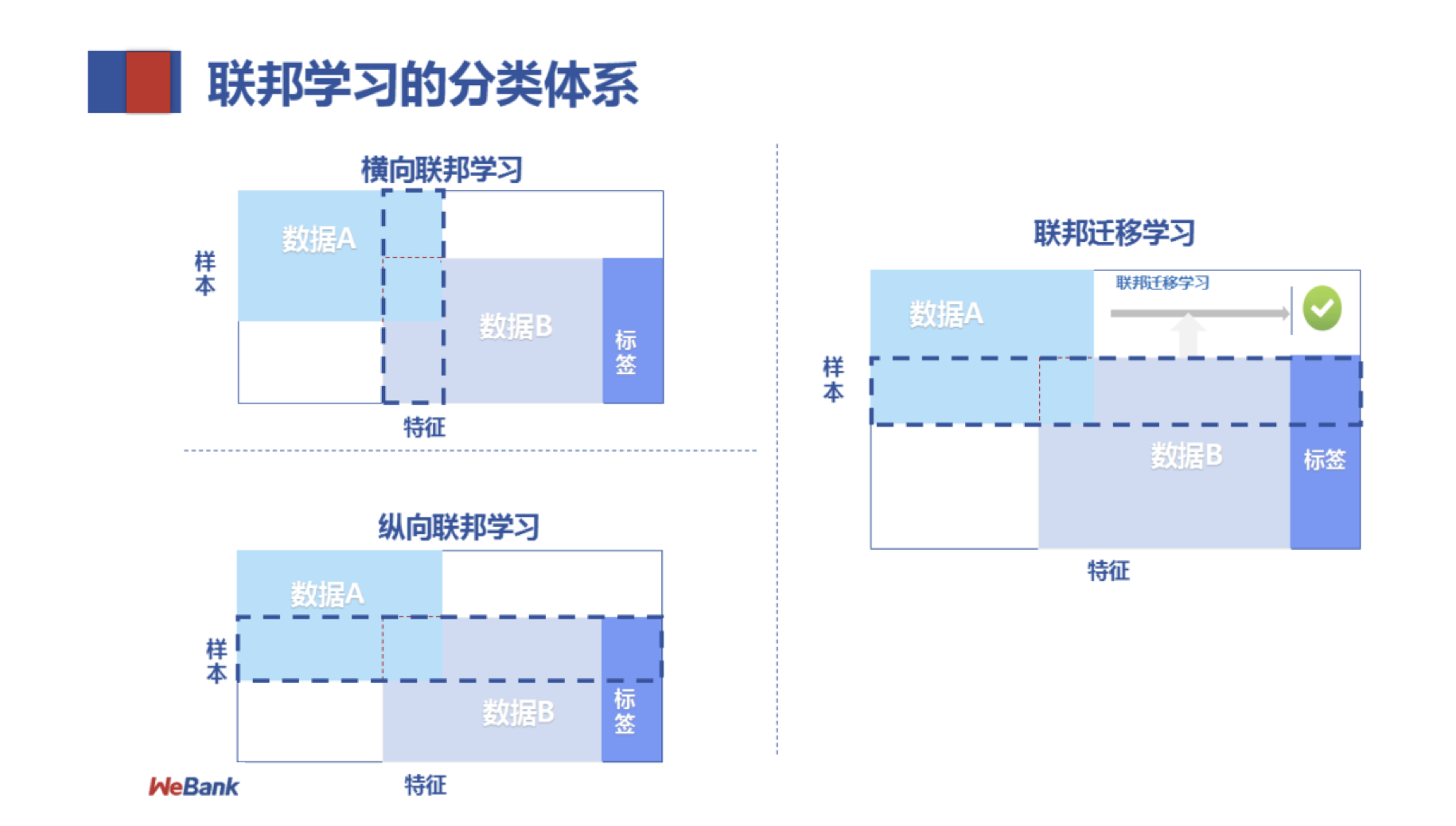
联邦学习的分类体系
根据各参与方数据源分布的不同,联邦学习可以被分为三类:横向联邦学习、纵向联邦学习以及联邦迁移学习。
图片来源:https://fate.fedai.org
✦1)横向联邦学习
由图可知,数据集的用户重叠部分小,但是特征重叠部分较大。例如两个地区的银行,他们客户的重叠度很小,但是客户的特征却相似度很高,即可通过横向联邦学习优化双方的模型。
✦2)纵向联邦学习
纵向联邦学习的本质是不同业务形态下的特征联合,适用于用户重叠多、特征重叠少的场景,比如电商和银行业务,它们触达的用户有大量重叠,但各自的用户特征表现却不同。
✦3)联邦迁移学习
适用于数据集的用户和用户特征重叠部分都比较小的情况,主要用于跨业务的模型聚合。比如银行业务中大额贷款和小额贷款的模型聚合,大额贷款的样本很少且增长较慢,用这样的数据训练出来的模型效果就会很差;小额贷款的样本就非常丰富。此种情况下,即可以采用联邦迁移学习将小额贷款的模型迁移到大额贷款上,高效进行模型训练和优化。
三、联邦学习初探
接下来,本文以业界应用更为广泛的纵向联邦学习展开,带大家了解如何进行联邦学习建模和优化。
纵向联邦学习建模的过程分两步走:
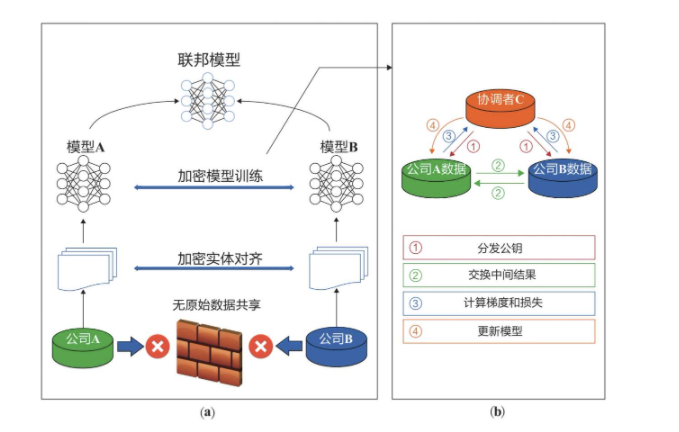
图:纵向联邦学习建模过程
图片来源:书籍《联邦学习》
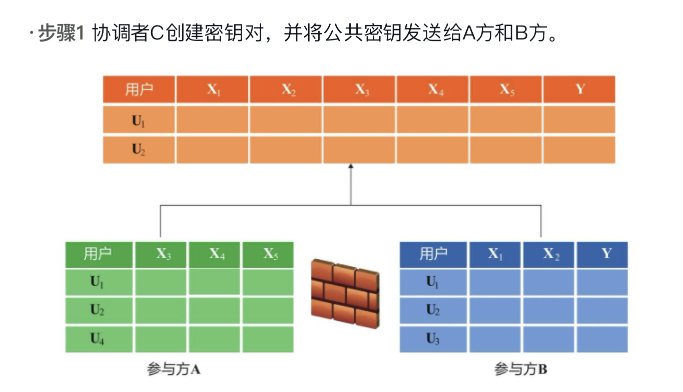
- 基于隐私保护的样本主键对齐
通过 RSA 和 Hash 的机制,保证双方最终只用到交集部分,且差集部分各自保留。

图片来源:https://fate.fedai.org
✦ B方把公钥n、e发往A;
✦ A方生成随机数,e作为随机数的指数,乘上自己样本的哈希值,得到Y(A)发给B方。因为样本加入的随机数,所以B方无法解密A方的原始数据;
✦ B方的私钥d当做Y(A)的指数,通过费马小定理,得到Za;
✦ B方对自己样本取哈希值,再用私钥d作为指数,再取一次哈希值,得到B数据哈希值d次方的哈希值Zb,连同Za一起返回给A。由于A不知道B的私钥d,所以他无法解开Zb,无法知晓B的原始数据;
✦ A方拿到Za后,先抵消自己的随机数,得到A数据哈希值的d次方,再做一次哈希得到Da;
✦ A方将Da和Zb取交集。因为两者都是数据哈希值d次方的哈希值;
✦ A方将交集返回给B方,双方各自获得交集数据。
- 基于同态加密的模型训练
图片来源:书籍《联邦学习》
在样本对齐后,各方可以使用这些交集的样本数据协同训练一个机器学习模型。
训练过程可以分为以下四个步骤:
✦ 协调者C生成公钥,将公钥分发给A方和B方;
✦ A方和B方将特征的中间结果(非原值)进行加密和互换。中间结果用来帮助计算梯度和损失值;
✦ A方和B方计算加密梯度并分别加入附加掩码。B方还会计算加密损失。A方和B方将加密结果发送给C方;
✦ C方对梯度的损失信息进行解密,并将结果发送回A方和B方。A方和B方解除信息上的掩码,并根据这些梯度信息来更新模型参数。
在这个过程中,没有明文数据传输,A方不知道B方的y值,同时双方也不知道对方的特征值是什么。
- 纵向联邦学习实战
了解了纵向联邦学习建模的原理和过程之后,就可以动手进行模型训练和优化啦!
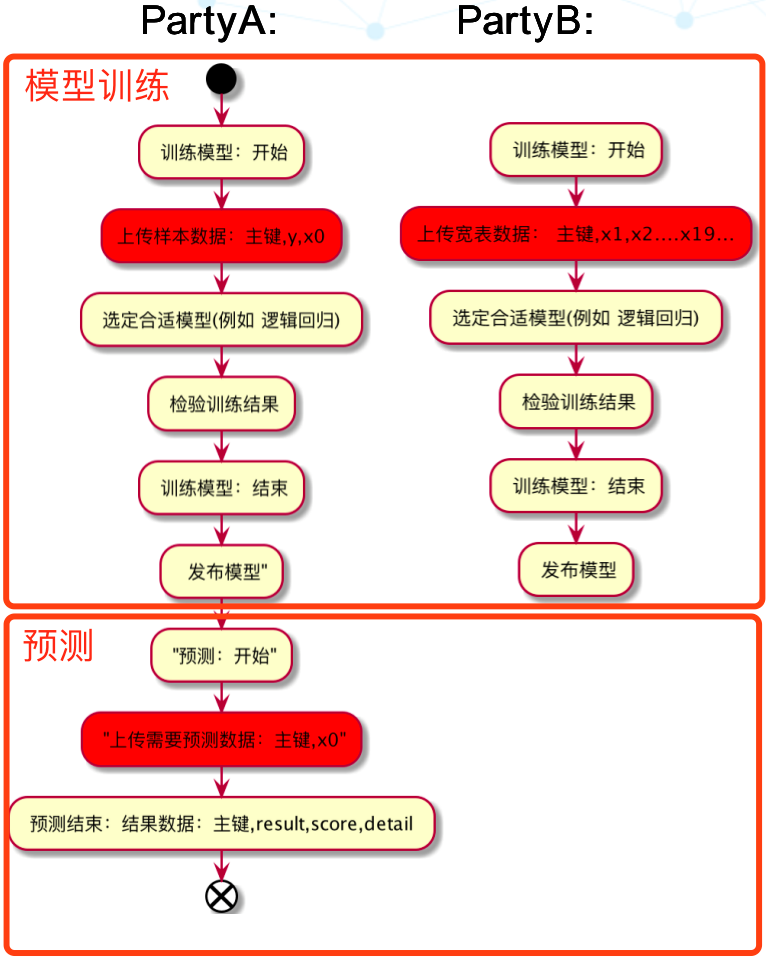
✦Step1:需要PartyA上传训练数据到本地集群;PartyB上传正式数据到本地集群,在合作建模时双方数据不会出库;
✦Step2:选择使用合适的算法训练模型,例如逻辑回归。此外,它还支持线性回归、泊松回归、CNN、DNN等常见算法;
✦Step3:发布在线推演模型用于后续正式数据的预测打标;
✦Step4:PartyA上传需要在线推演的正式数据;
✦Step5:PartyA通过PartyB返回的中间结果数据和协调者优化后的模型在本地集群进行结果预测。
性能评估过程:
系统输入几十万到百万条数据,通过6个节点(每个节点32核、64G)共同计算,在计算约30分钟后即可完成模型训练。我们将模型发布后,只需要分钟级别即可预测出千万条数据结果,高性能的模型训练和预测可以满足大部分的数据合作场景。
总结
在大数据和人工智能快速发展的背景下,联邦学习提供了一个有效的解决方案,使我们能够利用多方数据源和模型提升系统的效率,从而更好地让数据价值得以发挥。
个推也对“联邦学习”这一新型解决方案进行了实践,比如积极推进“中立国”计算模式的建立。该模式以“联邦学习”技术为核心,为开展联合建模和数据挖掘提供有效的安全防护,目前个推已在品牌营销等领域有相关实践成果落地。未来,个推还将在“联邦学习”领域继续深耕,打造全方位的大数据解决方案,助力行业深度挖掘数据价值。


 热门推荐
热门推荐
 视频中心
视频中心
 关注我们
关注我们

每日互动官方微信号
公司动态、品牌活动

个推官方微信号
新品发布、官方资讯

个推技术实践
技术干货、前沿科技